First order of business: an alternative to the Goodreads API
It's a bummer that Goodreads retired their API back in 2020.
Thankfully, Goodreads provides RSS feeds for each user shelf (also called a list), which means you can programmatically access data for all your books on Goodreads without having to rely on manually requesting a copy of your all data every so often (or some other hacky way of retrieving your data).
And best of all, we can use the sweet new Astro Content Loader API to handle retrieval and caching of said data from Goodreads — so we can simplify the whole development experience and focus on actually using the data in our Astro site (instead of worrying about how to retrieve it).
Here's how.
Note: your site needs to be on Astro 5.x to be able to use the Content Loader API.
If you're still on Astro 4.x and below, you can still retrieve the data using plain JavaScript (I've included a section on that near the end of this post) and then pass it to your components as props, but the Content Loader API is a much more elegant solution for handling data fetching and caching in Astro (so upgrading is recommended!).
If you're curious about what's possible with the Astro Content Loader API and Goodreads RSS feeds, check out the following pages on my blog that use the exact same setup as described in this post:
- /reading -- where I list my recently read books; and
- What I read in 2024 -- where I showcase my favourite books from the last year.
Goodreads RSS feeds
You can find the RSS feed that Goodreads generates for each user shelf in one of two ways:
- Scroll to the bottom on the list page and click on the little orange RSS icon to open the feed in a new tab with the url in the address bar (or just right-click on the icon and copy the url); or
- If you already have the url for the Goodreads shelf (e.g. https://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=read), then you can simply append
_rssto thelisttext in the url to get the RSS feed.
https://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=readhttps://www.goodreads.com/review/list_rss/152185079-sadman-hossain?shelf=readWhile Goodreads includes the user name in the list url, it only uses the account number preceding the name so the part of the url with the user name (e.g. -sadman-hossain) can be safely discarded.
https://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=readhttps://www.goodreads.com/review/list_rss/152185079?shelf=readHow Goodreads list urls work
The way list urls (and by corollary, RSS feed urls) work in Goodreads is that there is a base url for every user that points to their All bookshelf using their account number. The All bookshelf, as you can imagine, contains all the books stored in all of that user's bookshelves.
- e.g. my All bookshelf url is:
https://www.goodreads.com/review/list/152185079-sadman-hossain.
Every other bookshelf for a user (i.e. Read, Currently Reading, custom shelves) uses the same base url as the All bookshelf and then appends a suffix to the url like so: ...?shelf=<SHELF-NAME>.
This is nice because it means all you need to programmatically create urls for Goodreads bookshelves is the account number and any custom shelf names (the read, currently-reading, and want-to-read shelves are standard across all accounts) for a user.
.https://www.goodreads.com/review/list/152185079-sadman-hossain
https://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=readhttps://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=currently-readinghttps://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=want-to-read
https://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=pausedhttps://www.goodreads.com/review/list/152185079-sadman-hossain?shelf=software...I mention this little tidbit about Goodreads list urls because I once mistakenly removed the ...?shelf=read suffix from the base url of the Goodreads component on my blog's /reading page (which is supposed to only show my recently read books), and I was very confused at the results (which included books I hadn't even read) until I took a closer look at the urls.
Data schema
RSS feeds are just urls to raw XML files, so you can open them up in your browser and easily see how the data is stored and in what tags.
Of course, Goodreads RSS feeds use no stylesheets whatsoever, so parsing through the unformatted text is unwieldy.
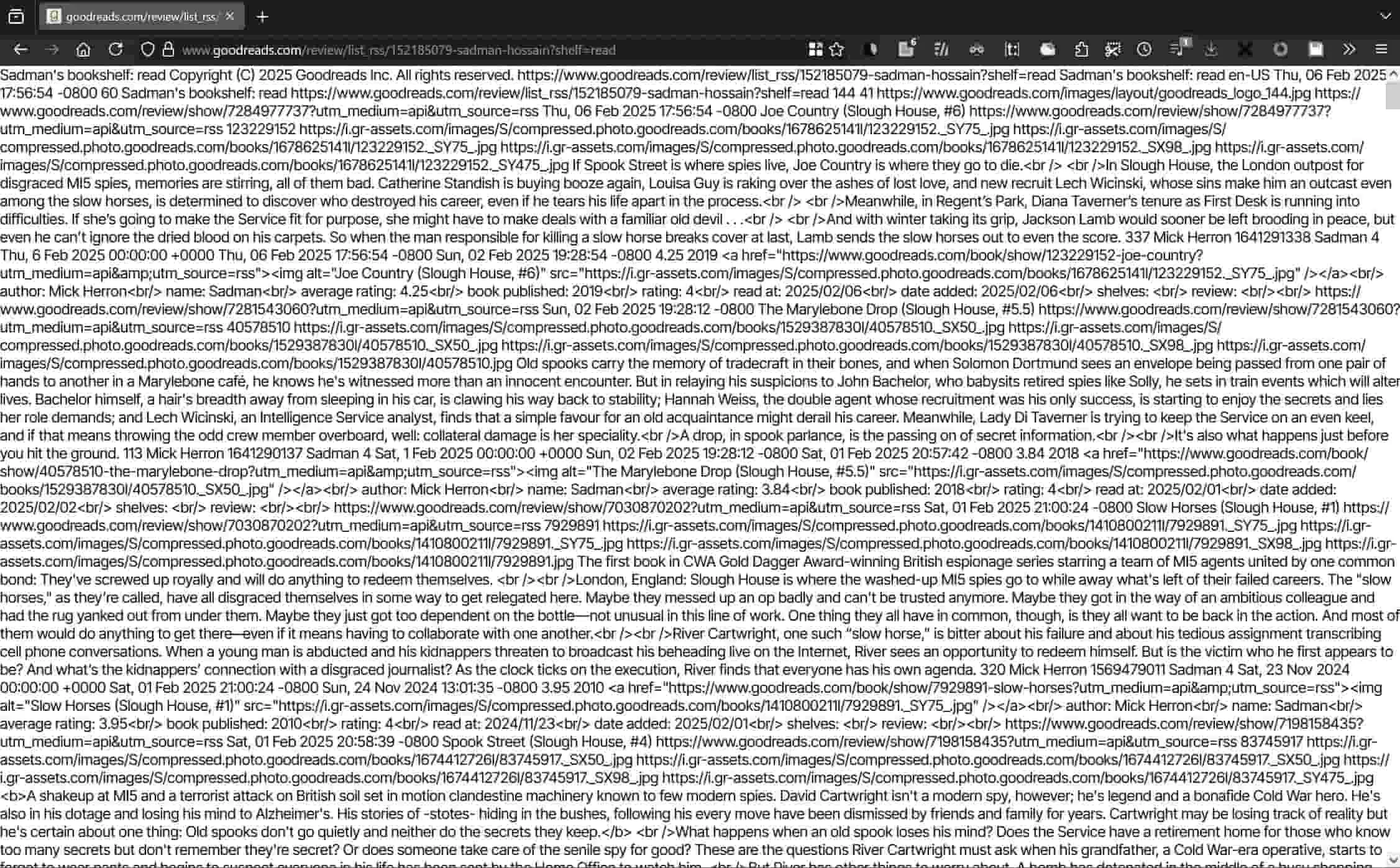
Run the XML code through a formatter and now we can get a better look at the data in the feed. In addition to the title and description of the bookshelf (at the very top of the XML file, hidden but revealable in the code snippet below), you can see that there's actually a fair amount of data for each book in the list:
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<xhtml:meta xmlns:xhtml="http://www.w3.org/1999/xhtml" name="robots" content="noindex" />
<title>Sadman's bookshelf: read</title>
<copyright><![CDATA[Copyright (C) 2025 Goodreads Inc. All rights reserved.]]>
</copyright>
<link><![CDATA[https://www.goodreads.com/review/list_rss/152185079?shelf=read]]></link>
<atom:link href="https://www.goodreads.com/review/list_rss/152185079?shelf=read" rel="self" type="application/rss+xml"/>
<description><![CDATA[Sadman's bookshelf: read]]></description>
<language>en-US</language>
<lastBuildDate>Thu, 06 Feb 2025 17:56:54 -0800</lastBuildDate>
<ttl>60</ttl>
<image>
<title>Sadman's bookshelf: read</title>
<link><![CDATA[https://www.goodreads.com/review/list_rss/152185079?shelf=read]]></link>
<width>144</width>
<height>41</height>
<url>https://www.goodreads.com/images/layout/goodreads_logo_144.jpg</url>
</image>
<item>
<guid><![CDATA[https://www.goodreads.com/review/show/7284977737?utm_medium=api&utm_source=rss]]></guid>
<pubDate><![CDATA[Thu, 06 Feb 2025 17:56:54 -0800]]></pubDate>
<title><![CDATA[Joe Country (Slough House, #6)]]></title>
<link><![CDATA[https://www.goodreads.com/review/show/7284977737?utm_medium=api&utm_source=rss]]></link>
<book_id>123229152</book_id>
<book_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg]]></book_image_url>
<book_small_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg]]></book_small_image_url>
<book_medium_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SX98_.jpg]]></book_medium_image_url>
<book_large_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY475_.jpg]]></book_large_image_url>
<book_description><![CDATA[If Spook Street is where spies live, Joe Country is where they go to die.<br /> <br />In Slough House, the London outpost for disgraced MI5 spies, memories are stirring, all of them bad. Catherine Standish is buying booze again, Louisa Guy is raking over the ashes of lost love, and new recruit Lech Wicinski, whose sins make him an outcast even among the slow horses, is determined to discover who destroyed his career, even if he tears his life apart in the process.<br /> <br />Meanwhile, in Regent’s Park, Diana Taverner’s tenure as First Desk is running into difficulties. If she’s going to make the Service fit for purpose, she might have to make deals with a familiar old devil . . .<br /> <br />And with winter taking its grip, Jackson Lamb would sooner be left brooding in peace, but even he can’t ignore the dried blood on his carpets. So when the man responsible for killing a slow horse breaks cover at last, Lamb sends the slow horses out to even the score.]]></book_description>
<book id="123229152">
<num_pages>337</num_pages>
</book>
<author_name>Mick Herron</author_name>
<isbn>1641291338</isbn>
<user_name>Sadman</user_name>
<user_rating>4</user_rating>
<user_read_at><![CDATA[Thu, 6 Feb 2025 00:00:00 +0000]]></user_read_at>
<user_date_added><![CDATA[Thu, 06 Feb 2025 17:56:54 -0800]]></user_date_added>
<user_date_created><![CDATA[Sun, 02 Feb 2025 19:28:54 -0800]]></user_date_created>
<user_shelves/>
<user_review/>
<average_rating>4.25</average_rating>
<book_published>2019</book_published>
<description>
<![CDATA[
<a href="https://www.goodreads.com/book/show/123229152-joe-country?utm_medium=api&utm_source=rss"><img alt="Joe Country (Slough House, #6)" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg" /></a><br/>
author: Mick Herron<br/>
name: Sadman<br/>
average rating: 4.25<br/>
book published: 2019<br/>
rating: 4<br/>
read at: 2025/02/06<br/>
date added: 2025/02/06<br/>
shelves: <br/>
review: <br/><br/>
]]>
</description>
</item>How about that, huh?
This is more than enough to put together a Goodreads bookshelf on your blog (or just list your recently read books), which leads into the next part of this post: loading Goodreads RSS data into Astro using the Content Loader API (and using plain old javascript for those still on Astro 4.x, too).
Astro Content Loader API
Quick introduction
In a nutshell, Astro's Content Loader API allows you to fetch (and, this is the cool part, cache) data from whereever you want. It can be a local source (like all a bunch of .mdx files in a folder in your codebase) or an external source (like data retrieved from an API, or in our case, from a file url).
Using the Content Loader API
Using the Content Loader API in your Astro project is actually really simple; you just need to:
- Write some code to define the content collection (which will store the data retrieved from your local or external source) in your project's content collection config file (usually
src/content.config.tsorsrc/content/config.ts); and then - Use the data from your new content collection however you want in your Astro components or pages (similar to how you may already be doing with
.mdxfiles for your blog posts or other web pages).
For your content collection, you will need to:
- use
defineCollection()to define the collection (and its source, local or external), which itself will...- ...have a
loaderobject (defines how to retrieve and parse the data). - ...have an optional
schema(defines data types and validation rules for the data).
- ...have a
- use
getCollection()to load the collection and its data into your Astro component or page.
While having a schema for your loader is optional, it's recommended (and helpful) because it will raise errors if the data retrieved from the source doesn't match the schema you've defined.
Astro uses Zod for all schema declaration and validation, so you can use the z object from the astro package to define your schema.
For more information on Zod, check out the Zod documentation.
You can define the loader directly within your content collection as an async function returning an array of entries. This simplifies data loading and storage, as the data store in Astro is cleared and reloaded each time the loader runs (without you having to manually deal with caching).
For a more detailed overview, take a look at the official Astro documentation on the Content Loader API.
Defining the content collection for Goodreads
For this post, I'll just show you how to define a content collection for a single Goodreads RSS feed (since that's what I'm using for my blog), but you can easily extend this to include multiple feeds (e.g. for multiple users or multiple shelves) by adding more entries to the content object in the content collection config file.
To start off, we'll need the xml2js package to parse the XML data from the Goodreads RSS feed into a JavaScript object. You can install it using npm by running:
npm install xml2jsNow, let's define the content collection for the Goodreads RSS feed:
import { defineCollection, z } from 'astro';import xml2js from 'xml2js'
const GOODREADS_URL = `https://www.goodreads.com/review/list_rss/152185079-sadman-hossain?shelf=read`
const goodreads_read_books = defineCollection({
schema: z.object({ id: z.string(), title: z.string(), date_read: z.string(), rating: z.string(), author_name: z.string(), book_image_url: z.string(), book_id: z.string(), }),
loader: async () => { const response = await fetch(GOODREADS_URL); const data = await response.text(); const result = await xml2js.parseStringPromise(data);
const goodreads_read_books = result.rss.channel[0].item.map((item: any) => { return { id: item.book_id[0], title: item.title[0], date_read: item.user_read_at[0], rating: item.user_rating[0], author_name: item.author_name[0], book_image_url: item.book_image_url[0], book_id: item.book_id[0], }; });
return goodreads_read_books; }});
...
export const collections = { goodreads_read_books, ...}Instead of storing your Goodreads RSS feed url directly in the content collection config file, you can store it in a separate file (e.g. src/consts.ts) and then import it into the content collection config file.
This way, you can easily change the url without having to modify the content collection config file.
...
export const GOODREADS_URL = `https://www.goodreads.com/review/list_rss/152185079-sadman-hossain?shelf=read`
...import { GOODREADS_URL } from './consts.ts'
...Note: the RSS feed for a Goodreads shelf will only include the last 100 books added to that shelf. This basically means that if you have more than 100 books in a shelf, you won't be able to retrieve all of them using a single RSS feed.
You can, however, create multiple shelves (e.g. read-2025, read-2026, etc.) and then retrieve the RSS feed for each shelf to get all your books.
The beauty of Astro's Content Loader API is that you can define a single content collection that has a loader object fetching from each of these shelves, so you only need to reference a single collection when you're using that data in your components or pages.
Using the Goodreads collection in your Astro components
Unstyled
Now that you've defined the content collection for the Goodreads RSS feed, you can use it by defining it in the frontmatter of your Astro components or pages.
The Goodreads collection data is an array of objects, so you can use the map() function to iterate over the data and display each book in the list.
---
import { getCollection } from 'astro:content'
import Layout from '@/layouts/layout.astro';
const books = await getCollection('goodreads_read_books')
---
<Layout title="Goodreads Books" description="A list of books I've recently read from Goodreads.">
<ul>
{books.map((book) => (
<li>
<h2>{book.data.title}</h2>
<p>Author: {book.data.author_name}</p>
<p>Rating: {book.data.rating}</p>
<p>Date Read: {book.data.date_read}</p>
<img src={book.data.book_image_url} alt={book.data.title} />
</li>
))}
</ul>
</Layout>

Styling with Tailwind CSS
Add some basic Tailwind CSS classes to style the component and you're on the road to building something that looks really good (for surprisingly little effort).
Show Source
---
import { getCollection } from 'astro:content'
import Layout from '@/layouts/layout.astro';
const books = await getCollection('goodreads_read_books')
---
<Layout title="Goodreads Books" description="A list of books I've recently read from Goodreads.">
<div class="grid grid-cols-1 sm:grid-cols-2 md:grid-cols-3 lg:grid-cols-4 gap-4 mx-8 text-center">
{books.map((book) => (
<div class="p-4 border-4 border-gray-600 rounded-xl">
<h2 class="text-xl font-semibold mb-2">
{book.data.title}
</h2>
<p class="text-gray-600">
Author: {book.data.author_name}
</p>
<p class="text-gray-600">
Rating: {book.data.rating}
</p>
<p class="text-gray-400">
Date Read: {book.data.date_read}
</p>
<div class="flex justify-center">
<img class="mt-2 rounded-lg"
src={book.data.book_image_url}
alt={book.data.title}
/>
</div>
</div>
))}
</div>
</Layout>

The Goodreads component I built for my blog is a bit more complex than the one above (it includes filtering and sorting functionality; I explain how that's implemented in the next section), but the basic idea is the same: now that the data has been stored in the content collection, you can use it in your Astro components and pages however you want.
Show Source
---
import { Image } from 'astro:assets'
import { getCollection } from 'astro:content'
type Book = {
data: {
id: string
title: string
shelves: string[]
date_read: string
rating: string
author_name: string
book_image_url: string
book_id: string
}
}
type Props = {
gridMarginTop?: number
titleMarginTop?: number
ratingMarginBottom?: number
filterYear?: number
filterTitles?: string[]
}
const {
gridMarginTop = 4,
titleMarginTop = 1,
ratingMarginBottom = 4,
filterYear,
filterTitles,
} = Astro.props
let books = await getCollection('goodreads_read_books')
// Filter books by year if filterYear is provided
if (filterYear) {
books = books.filter((book: Book) => {
const date = new Date(book.data.date_read)
return date.getUTCFullYear() === filterYear
})
}
// Filter books by title if filterTitles is provided
if (filterTitles && filterTitles.length > 0) {
books = books.filter((book: Book) => filterTitles.includes(book.data.title))
// Sort books by the order of titles in filterTitles
books.sort(
(a: Book, b: Book) =>
filterTitles.indexOf(a.data.title) - filterTitles.indexOf(b.data.title),
)
}
// Sort books by date_read (latest first) if not filtering by titles
if (!filterTitles || filterTitles.length === 0) {
books.sort((a: Book, b: Book) => {
if (!a.data.date_read || a.data.date_read[0] === '') return -1 // Place a at the top if date_read is missing
if (!b.data.date_read || b.data.date_read[0] === '') return 1 // Place b at the top if date_read is missing
const dateA = new Date(a.data.date_read)
const dateB = new Date(b.data.date_read)
return dateB.getTime() - dateA.getTime()
})
}
function formatDate(dateString: any) {
const monthNames = [
'Jan',
'Feb',
'Mar',
'Apr',
'May',
'Jun',
'Jul',
'Aug',
'Sep',
'Oct',
'Nov',
'Dec',
]
const date = new Date(dateString)
const day = date.getUTCDate()
const month = monthNames[date.getUTCMonth()]
const year = date.getUTCFullYear()
return `${day} ${month} ${year}`
}
---
<style>
.line-clamp-2 {
display: -webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
overflow: hidden;
}
.placeholder {
display: flex;
align-items: center;
justify-content: center;
width: 100%;
height: 100%;
opacity: 1;
transition: opacity 0.5s ease-in-out;
position: relative;
z-index: 1;
}
.zoomable-image {
opacity: 0;
transition: opacity 0.5s ease-in-out;
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 2;
}
.zoomable-image.loaded {
opacity: 1;
}
</style>
<div class={`mt-${gridMarginTop} goodreads`}>
<div
class="grid grid-cols-3 gap-2 sm:grid-cols-6 md:grid-cols-7 lg:grid-cols-7 xl:grid-cols-7"
>
{
books.map((book: Book) => (
<div class="flex flex-col items-center">
<a
href={`https://www.goodreads.com/book/show/${book.data.book_id}`}
class="h-36 w-24"
target="_blank"
>
<div class="hover-card relative h-full w-full">
<div
class="placeholder rounded-lg bg-gray-300 dark:bg-gray-800"
id={`placeholder-${book.data.book_id}`}
>
<div class="h-12 w-12 rounded-3xl bg-gray-200 dark:bg-gray-700" />
</div>
<Image
src={book.data.book_image_url}
alt={book.data.title}
class="zoomable-image h-full w-full rounded-md object-cover"
title={`${book.data.title}`}
width={101}
height={150}
onload={`document.getElementById('placeholder-${book.data.book_id}').classList.add('hidden'); this.classList.add('loaded');`}
/>
</div>
</a>
<div class={`mt-${titleMarginTop} text-center`}>
<a
href={`https://www.goodreads.com/book/show/${book.data.book_id}`}
class="w-24 line-clamp-2 block text-xs font-semibold underline"
style="text-underline-offset: 2px;"
target="_blank"
title={`${book.data.title}`}
>
{book.data.title}
</a>
<span
class="w-24 mt-1 block truncate text-xs text-muted-foreground"
title={`${book.data.author_name}`}
>
{book.data.author_name}
</span>
{book.data.date_read[0] !== '' && (
<span
class="block text-xs text-muted-foreground"
title="Date read"
>
{formatDate(book.data.date_read)}
</span>
)}
<div
class={`mb-${ratingMarginBottom} flex items-center justify-center`}
title={`Rating given: ${book.data.rating}/5 stars`}
>
{Array.from({ length: 5 }, (_, i) => (
<svg
class={`h-4 w-4 ${i < Number(book.data.rating) ? 'text-black-500 dark:text-white' : 'text-gray-200 dark:text-gray-700'}`}
fill="currentColor"
viewBox="0 0 20 20"
>
<path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.286 3.957a1 1 0 00.95.69h4.163c.969 0 1.371 1.24.588 1.81l-3.37 2.448a1 1 0 00-.364 1.118l1.286 3.957c.3.921-.755 1.688-1.54 1.118l-3.37-2.448a1 1 0 00-1.175 0l-3.37 2.448c-.784.57-1.84-.197-1.54-1.118l1.286-3.957a1 1 0 00-.364-1.118L2.174 9.384c-.783-.57-.38-1.81.588-1.81h4.163a1 1 0 00.95-.69l1.286-3.957z" />
</svg>
))}
</div>
</div>
</div>
))
}
</div>
</div>

")
")
")
")
")
")



")


You can use a similar content loader setup to retrieve data from other sources (like APIs) too.
I reused a large portion of the code above to create a similar component for my trakt.tv data (on my watched movies and TV shows) and it was a breeze to set up.
- What I watched in 2024 -- my favourite movies and TV shows of 2024 (and others).
Filtering & sorting collection entries
The content collection we created with Goodreads books is just an array of objects, so you can use the filter() function to filter out books based on certain criteria (e.g. only show books that you rated 5 stars or read in the current year) or the sort() function to sort the books based on certain criteria (e.g. sort by descending rating or date read).
Here's what I use in the GoodreadsGrid.astro component on my Astro site to:
- filter books by a list of provided titles (i.e. only show books that are in the list of titles provided in the
filterTitlesprop); - sort the books by descending date read (i.e. show the most recently read books first); and
- transform the date read value from the Goodreads RSS feed into a more readable format (e.g. to
Jan 31, 2025).
---
import { Image } from 'astro:assets'
import { getCollection } from 'astro:content'
type Book = {
data: {
id: string
title: string
shelves: string[]
date_read: string
rating: string
author_name: string
book_image_url: string
book_id: string
}
}
type Props = {
gridMarginTop?: number
titleMarginTop?: number
ratingMarginBottom?: number
filterYear?: number
filterTitles?: string[]
}
const {
gridMarginTop = 4,
titleMarginTop = 1,
ratingMarginBottom = 4,
filterYear,
filterTitles,
} = Astro.props
let books = await getCollection('goodreads_read_books')
// Filter books by year if filterYear is provided
if (filterYear) {
books = books.filter((book: Book) => {
const date = new Date(book.data.date_read)
return date.getUTCFullYear() === filterYear
})
}
// Filter books by title if filterTitles is provided
if (filterTitles && filterTitles.length > 0) {
books = books.filter((book: Book) => filterTitles.includes(book.data.title))
// Sort books by the order of titles in filterTitles
books.sort(
(a: Book, b: Book) =>
filterTitles.indexOf(a.data.title) - filterTitles.indexOf(b.data.title),
)
}
// Sort books by date_read (latest first) if not filtering by titles
if (!filterTitles || filterTitles.length === 0) {
books.sort((a: Book, b: Book) => {
if (!a.data.date_read || a.data.date_read[0] === '') return -1 // Place a at the top if date_read is missing
if (!b.data.date_read || b.data.date_read[0] === '') return 1 // Place b at the top if date_read is missing
const dateA = new Date(a.data.date_read)
const dateB = new Date(b.data.date_read)
return dateB.getTime() - dateA.getTime()
})
}
function formatDate(dateString: any) {
const monthNames = [
'Jan',
'Feb',
'Mar',
'Apr',
'May',
'Jun',
'Jul',
'Aug',
'Sep',
'Oct',
'Nov',
'Dec',
]
const date = new Date(dateString)
const day = date.getUTCDate()
const month = monthNames[date.getUTCMonth()]
const year = date.getUTCFullYear()
return `${day} ${month} ${year}`
}
---
<style>
.line-clamp-2 {
display: -webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
overflow: hidden;
}
.placeholder {
display: flex;
align-items: center;
justify-content: center;
width: 100%;
height: 100%;
opacity: 1;
transition: opacity 0.5s ease-in-out;
position: relative;
z-index: 1;
}
.zoomable-image {
opacity: 0;
transition: opacity 0.5s ease-in-out;
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 2;
}
.zoomable-image.loaded {
opacity: 1;
}
</style>
<div class={`mt-${gridMarginTop} goodreads`}>
<div
class="grid grid-cols-3 gap-2 sm:grid-cols-6 md:grid-cols-7 lg:grid-cols-7 xl:grid-cols-7"
>
{
books.map((book: Book) => (
<div class="flex flex-col items-center">
<a
href={`https://www.goodreads.com/book/show/${book.data.book_id}`}
class="h-36 w-24"
target="_blank"
>
<div class="hover-card relative h-full w-full">
<div
class="placeholder rounded-lg bg-gray-300 dark:bg-gray-800"
id={`placeholder-${book.data.book_id}`}
>
<div class="h-12 w-12 rounded-3xl bg-gray-200 dark:bg-gray-700" />
</div>
<Image
src={book.data.book_image_url}
alt={book.data.title}
class="zoomable-image h-full w-full rounded-md object-cover"
title={`${book.data.title}`}
width={101}
height={150}
onload={`document.getElementById('placeholder-${book.data.book_id}').classList.add('hidden'); this.classList.add('loaded');`}
/>
</div>
</a>
<div class={`mt-${titleMarginTop} text-center`}>
<a
href={`https://www.goodreads.com/book/show/${book.data.book_id}`}
class="w-24 line-clamp-2 block text-xs font-semibold underline"
style="text-underline-offset: 2px;"
target="_blank"
title={`${book.data.title}`}
>
{book.data.title}
</a>
<span
class="w-24 mt-1 block truncate text-xs text-muted-foreground"
title={`${book.data.author_name}`}
>
{book.data.author_name}
</span>
{book.data.date_read[0] !== '' && (
<span
class="block text-xs text-muted-foreground"
title="Date read"
>
{formatDate(book.data.date_read)}
</span>
)}
<div
class={`mb-${ratingMarginBottom} flex items-center justify-center`}
title={`Rating given: ${book.data.rating}/5 stars`}
>
{Array.from({ length: 5 }, (_, i) => (
<svg
class={`h-4 w-4 ${i < Number(book.data.rating) ? 'text-black-500 dark:text-white' : 'text-gray-200 dark:text-gray-700'}`}
fill="currentColor"
viewBox="0 0 20 20"
>
<path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.286 3.957a1 1 0 00.95.69h4.163c.969 0 1.371 1.24.588 1.81l-3.37 2.448a1 1 0 00-.364 1.118l1.286 3.957c.3.921-.755 1.688-1.54 1.118l-3.37-2.448a1 1 0 00-1.175 0l-3.37 2.448c-.784.57-1.84-.197-1.54-1.118l1.286-3.957a1 1 0 00-.364-1.118L2.174 9.384c-.783-.57-.38-1.81.588-1.81h4.163a1 1 0 00.95-.69l1.286-3.957z" />
</svg>
))}
</div>
</div>
</div>
))
}
</div>
</div>
Retrieving Goodreads data without the Content Loader API
If you're still on Astro 4.x and below, you can't use the Content Loader API to retrieve data from Goodreads, but you can still use JavaScript to fetch the data and then pass it to your components as props.
import xml2js from 'xml2js'
const TIMEOUT = 200000; // Set timeout to 200 secondsconst REQUEST_DELAY = 500;
const delay = (ms: number) => new Promise(resolve => setTimeout(resolve, ms));
const fetchWithTimeout = async (url: string, options = {}, timeout = TIMEOUT) => { await delay(REQUEST_DELAY); const controller = new AbortController(); const id = setTimeout(() => controller.abort(), timeout); const response = await fetch(url, { ...options, signal: controller.signal }); clearTimeout(id); return response;};
const GOODREADS_URL = import.meta.env.GOODREADS_URL;const response = await fetchWithTimeout(GOODREADS_URL);
const data = await response.text()const result = await xml2js.parseStringPromise(data)let books = result.rss.channel[0].item.map((item: any) => { return { title: item.title[0], shelves: item.user_shelves, date_read: item.user_read_at, rating: item.user_rating[0], author_name: item.author_name, book_image_url: book_image_url[0], book_id: item.book_id[0], }})
...This is actually what I used to do before I upgraded to Astro 5.x and started using the Content Loader API, but it was a bit of a pain to use sometimes because it meant that whenever I ran npm run dev I had to wait for the data to be fetched after every single change on my site. Because the data fetching was done in the component itself, it was re-fetched every time the component was re-rendered.
While that's not a big deal (beyond being poor practice) since it was just retrieving and parsing an XML file, it was faaar more painful when I tried to use the same approach for loading data using APIs with rate limits (which often broke components while I was trying to test them in dev). In fact, that was the catalyst for me to upgrade to Astro 5.x and start using the Content Loader API.
Why you can't use the Astro feed loader to fetch Goodreads data
While the @ascorbic/feed-loader package does allow you to load data from RSS feeds similar to how we did above, the package has a very limited schema that does not allow for the kind of complex data retrieval and parsing that we need to do for Goodreads data (which results in most of the fields in the Goodreads RSS feed being ignored and little actual data being retrieved).
import { z } from 'astro/zod'
export const NSSchema = z.record(z.string(), z.string())
export const ImageSchema = z.object({
url: z.string().optional(),
title: z.string().optional(),
});
export const MetaSchema = z.object({
"#ns": z.array(NSSchema),
"#type": z.enum(["atom", "rss", "rdf"]),
"#version": z.string(),
title: z.string(),
description: z.string().nullable(),
date: z.coerce.date().nullable(),
pubdate: z.coerce.date().nullable(),
link: z.string().nullable(),
xmlurl: z.string().nullable(),
author: z.string().nullable(),
language: z.string().nullable(),
image: ImageSchema.nullable(),
favicon: z.string().nullable(),
copyright: z.string().nullable(),
generator: z.string().nullable(),
categories: z.array(z.string()),
});
// Enclosure schema
export const EnclosureSchema = z.object({
length: z.string().nullable().optional(),
type: z.string().nullable().optional(),
url: z.string(),
});
// Item schema
export const ItemSchema = z.object({
title: z.string().nullable(),
description: z.string().nullable(),
summary: z.string().nullable(),
date: z.coerce.date().nullable(),
pubdate: z.coerce.date().nullable(),
link: z.string().nullable(),
origlink: z.string().nullable(),
author: z.string().nullable(),
guid: z.string(),
comments: z.string().nullable(),
image: ImageSchema,
categories: z.array(z.string()),
enclosures: z.array(EnclosureSchema),
meta: MetaSchema,
});
type Simplify<T> = {
[P in keyof T]: T[P];
};
export type NS = z.infer<typeof NSSchema>;
export type Image = z.infer<typeof ImageSchema>;
export type Meta = z.infer<typeof MetaSchema>;
export type Enclosure = z.infer<typeof EnclosureSchema>;
export type Item = Simplify<
z.infer<typeof ItemSchema> & {
[key: string]: unknown;
}
>;
Show XML Code for Goodreads RSS Feed
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom">
<channel>
<xhtml:meta xmlns:xhtml="http://www.w3.org/1999/xhtml" name="robots" content="noindex" />
<title>Sadman's bookshelf: read</title>
<copyright><![CDATA[Copyright (C) 2025 Goodreads Inc. All rights reserved.]]>
</copyright>
<link><![CDATA[https://www.goodreads.com/review/list_rss/152185079?shelf=read]]></link>
<atom:link href="https://www.goodreads.com/review/list_rss/152185079?shelf=read" rel="self" type="application/rss+xml"/>
<description><![CDATA[Sadman's bookshelf: read]]></description>
<language>en-US</language>
<lastBuildDate>Thu, 06 Feb 2025 17:56:54 -0800</lastBuildDate>
<ttl>60</ttl>
<image>
<title>Sadman's bookshelf: read</title>
<link><![CDATA[https://www.goodreads.com/review/list_rss/152185079?shelf=read]]></link>
<width>144</width>
<height>41</height>
<url>https://www.goodreads.com/images/layout/goodreads_logo_144.jpg</url>
</image>
<item>
<guid><![CDATA[https://www.goodreads.com/review/show/7284977737?utm_medium=api&utm_source=rss]]></guid>
<pubDate><![CDATA[Thu, 06 Feb 2025 17:56:54 -0800]]></pubDate>
<title><![CDATA[Joe Country (Slough House, #6)]]></title>
<link><![CDATA[https://www.goodreads.com/review/show/7284977737?utm_medium=api&utm_source=rss]]></link>
<book_id>123229152</book_id>
<book_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg]]></book_image_url>
<book_small_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg]]></book_small_image_url>
<book_medium_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SX98_.jpg]]></book_medium_image_url>
<book_large_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY475_.jpg]]></book_large_image_url>
<book_description><![CDATA[If Spook Street is where spies live, Joe Country is where they go to die.<br /> <br />In Slough House, the London outpost for disgraced MI5 spies, memories are stirring, all of them bad. Catherine Standish is buying booze again, Louisa Guy is raking over the ashes of lost love, and new recruit Lech Wicinski, whose sins make him an outcast even among the slow horses, is determined to discover who destroyed his career, even if he tears his life apart in the process.<br /> <br />Meanwhile, in Regent’s Park, Diana Taverner’s tenure as First Desk is running into difficulties. If she’s going to make the Service fit for purpose, she might have to make deals with a familiar old devil . . .<br /> <br />And with winter taking its grip, Jackson Lamb would sooner be left brooding in peace, but even he can’t ignore the dried blood on his carpets. So when the man responsible for killing a slow horse breaks cover at last, Lamb sends the slow horses out to even the score.]]></book_description>
<book id="123229152">
<num_pages>337</num_pages>
</book>
<author_name>Mick Herron</author_name>
<isbn>1641291338</isbn>
<user_name>Sadman</user_name>
<user_rating>4</user_rating>
<user_read_at><![CDATA[Thu, 6 Feb 2025 00:00:00 +0000]]></user_read_at>
<user_date_added><![CDATA[Thu, 06 Feb 2025 17:56:54 -0800]]></user_date_added>
<user_date_created><![CDATA[Sun, 02 Feb 2025 19:28:54 -0800]]></user_date_created>
<user_shelves/>
<user_review/>
<average_rating>4.25</average_rating>
<book_published>2019</book_published>
<description>
<![CDATA[
<a href="https://www.goodreads.com/book/show/123229152-joe-country?utm_medium=api&utm_source=rss"><img alt="Joe Country (Slough House, #6)" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1678625141l/123229152._SY75_.jpg" /></a><br/>
author: Mick Herron<br/>
name: Sadman<br/>
average rating: 4.25<br/>
book published: 2019<br/>
rating: 4<br/>
read at: 2025/02/06<br/>
date added: 2025/02/06<br/>
shelves: <br/>
review: <br/><br/>
]]>
</description>
</item>Closing notes
It's incredible how much you can do with the Astro Content Loader API and a little bit of creativity. I'm really glad that Goodreads provides RSS feeds for their bookshelves because otherwise I feel like there's really no other easy way of accessing your data programmatically (short of exporting your data, which would be a massive pain to do on a regular basis).
I've been tracking my read (and want-to-read) books on Goodreads since early 2023 (ever since I got my hands on an ereader), and it's really nice to be able to display them on my blog so that I can share my experiences with others (as you might have concluded, I absolutely love reading).
I've been looking for a way to do this for a while now, and it's been disappointing scouring the web and searching using terms like "react goodreads component" or "astro goodreads component" and coming up with nothing particularly helpful, so I'm really happy with what has been made possible by the Astro team.
What's next?
I already use a Goodreads component on my blog's /reading page to show my recently read books, and I also used it extensively in my "What I read in 2024" post to showcase my favourite books from the last year.
I thought I already knew a lot about the Content Loader API, but from taking another look at the docs while writing this post I notice that there's a couple of features I haven't used yet (like object loaders to control how long to cache data), so I'm excited to optimize how I use the Content Loader API on my site even more and see what else I can get up to with it in the future.
Special thanks to the following posts for introducing me to the idea of using Goodreads RSS feeds to retrieve data and helping me figure out how to set this all up:
- Using Goodreads Data in Eleventy -- Raymond Camden
- Custom Goodreads Bookshelf Rendering in Astro -- Isak Solheim