UofT PEY Co-op
Whether you're a new applicant to engineering/computer science at the University of Toronto (UofT) or someone who's going through their 1st, 2nd, or even 3rd or 4th years, you've probably been curious at one point or another about what 12-16 month job positions are actually posted on the much acclaimed PEY Co-op job board.
Well, as a computer engineering student at UofT who's just finished their third year (and consequently have been able to access the portal for the entire past two semesters), I thought it would be interesting to do my own data collection on the topic, along with some analysis on recurring patterns (e.g. locations, international opportunities, etc.), and share both my findings and the raw data (thousands of jobs posted across several months) so that future PEY Co-op students can get a better idea of what to expect from the portal.
SELECT * FROM JobPostings LIMIT 5;| id | postingDate | title | company | companyDivision | companyWebsite | location | locationType | numPositions | salary | startDate | endDate | function | applicationDeadline | |-------|-------------|--------------------------------------|----------------------------------|-----------------|----------------------------------------------------|--------------|-----------------------|--------------|----------------------------------------|------------|------------|------------------------|---------------------------| | 43541 | 2023-09-17 | Business Insights Analyst | Air Canada | Main Division | www.aircanada.com | Brampton | Hybrid: 3 days on-site | 1 | 0.00 hourly for 0.0 hours per week | 05/06/2024 | 04/25/2025 | Engineering | Oct 6, 2023 11:59 PM | | 44010 | 2023-09-17 | Software Engineering Intern | GGY a Moodys Analytics Company | AXIS | moodysanalytics.com | Toronto | On-Site | 1 | Salary Not Available, 40.0 hours per week | 05/06/2024 | 09/08/2025 | Information Technology (IT) | Sep 29, 2023 11:59 PM | | 44045 | 2023-09-17 | Compute Kernel Development Engineering Intern | Untether AI | Main Office | untether.ai | Toronto | On-Site | 1 | Salary Not Available, 40.0 hours per week | 05/06/2024 | 04/25/2025 | Engineering | Oct 8, 2023 11:59 PM |
Scraping job posting data
The UofT PEY Co-op job board itself is located behind a login portal at https://www.uoftengcareerportal.ca/notLoggedIn. To get in, you need to:
- be a student at UofT (to have valid login credentials);
- be enrolled in the PEY Co-op program; and
- be registered to start your 12-16 month internship sometime between May and September following your current year.
All of which means that unless you're a keen student in your second year who's opted in to get access and do your PEY early, you're either in your third year or you don't have access to the job portal. As an engineering student who's just finished their third year (at the time of writing), I've had privileged access for 8 months and counting, and I've been able to save data on every single job posted on the portal since the very first day I've had access (I came prepared).
What you can expect from the job board
The landing page for the PEY Co-op job board has the same look as the one for all the cross-institutional job boards at UofT's Career Learning Network (CLNx) and uses the same organization of elements and processes for browsing, searching for, and applying to job postings, so if you're a UofT student who's used CLNx in the past (e.g. for applying to work study positions) then you already know what it's like to experience using the PEY job board (from what I've seen on Reddit, I'm pretty sure WaterlooWorks uses the same frontend as well).
Sample job postings
Your average PEY job postings look like the below.
Note: The design on the left was used for a couple years, until the most recent redesign in late 2023 (which took place halfway through my fall semester of third year). If you're an upcoming PEY Co-op student, job postings should look like the image on the right for you (Edit 2024-11-14: the job board has been redesigned again, and now looks unlike either image; check out my post on 2024-2025 UofT Co-op job postings to see what they look like now).
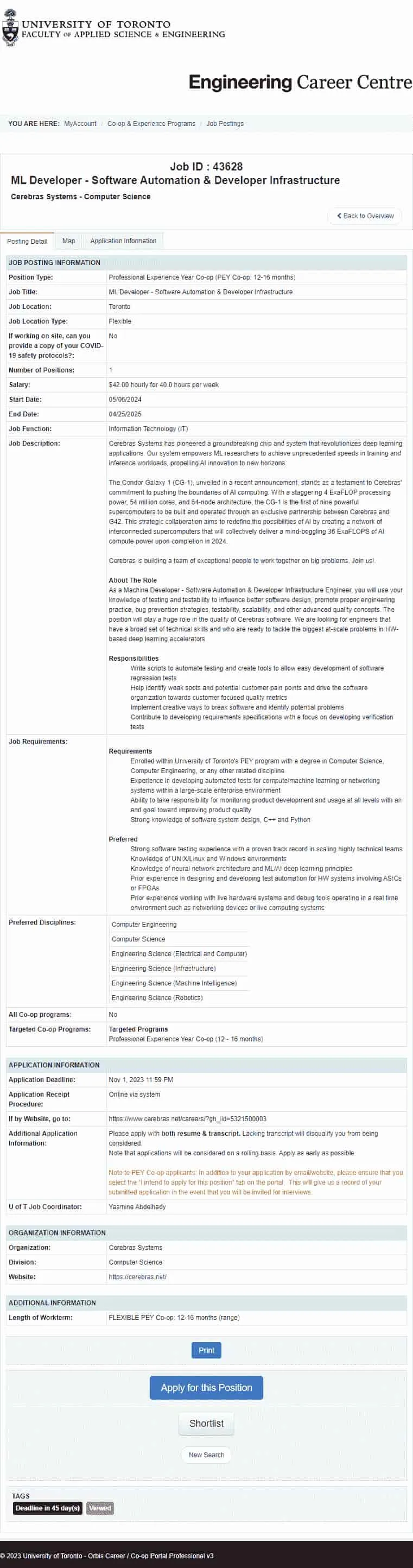
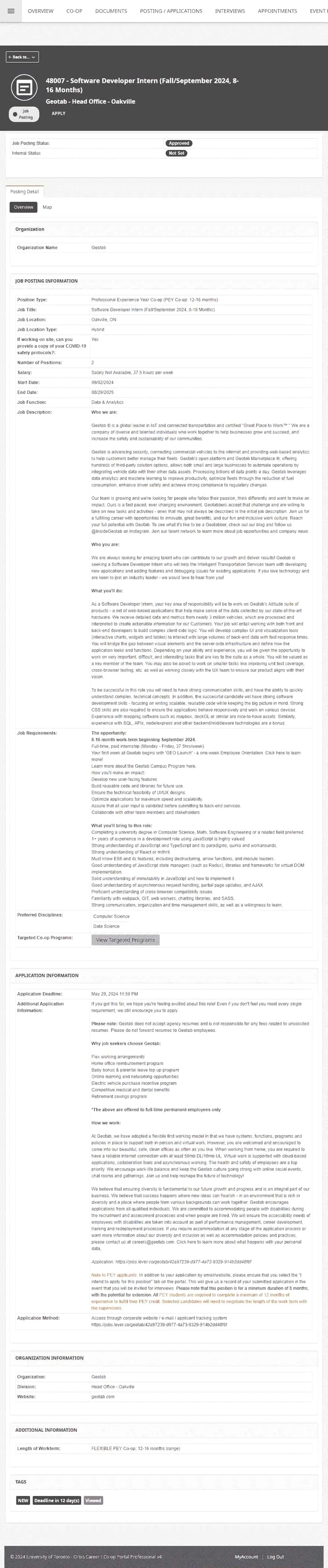
Nothing much to look at, just some basic tables with information about the job and the company, which thankfully are simple to parse.
Getting the posting date for jobs
One thing that's been important to me since the very start of this project is making sure that the timestamps of job postings are available to view. As someone who took a few months before I landed a position that I was really satisfied with, there were times where I felt a bit apprehensive at turning down offers for roles that I thought were fine but didn't feel excited about. I had no data beyond anecdotes from upper years about what's posted over the course of the fall and winter semesters, and so I couldn't really predict whether that dream role I had in mind was just a couple days from being posted (or whether jobs would start drying up so I should stick with whatever I had at that point in time), which is why I hope that at least one of the things this project of mine can provide is some reassurance to future PEY students about what jobs are posted and when.
One thing to keep in mind: every year is different, and just because some company posted some number of jobs at some point in time doesn't mean that they'll do it again next year. Of course, it also doesn't mean that they won't do it again, so make sure your takeaways from the data are taken with a grain of salt.
There's just one problem: there's absolutely no data indicating when a job was posted.
Well, except for one thing: the New Posting Since Last Login button on the landing page.
Whenever you login to the portal, that New Posting Since Last Login button gets updated with links to all of the jobs posted since your last login, so if you were to check the job board every single day and save the data for all of the job postings shown there each time you login, well, then you've successfully attributed a posting data for every single job.
Which is why that's exactly what I've done for the 263 days that I've had access to the portal (from 2023-09-17 to 2024-06-06).
How I've been saving posting dates for jobs
It's all thanks to Gildas Lormeau's SingleFile web extension, which allows for saving a complete web page into a single HTML file (unlike Chrome[^chrome]). In addition (and rather importantly), the SingleFile extension allows for saving pages for all tabs in the current window (this is important for making the whole archival process a not-headache). While SingleFile is also usable as a CLI, the tricky navigation for the PEY job board website means that manually navigating to pages & then saving them using the extension is a lot easier.
[^chrome]: Chrome and virtually all other browsers have a slightly more complicated setup for saving pages which makes organizing files for saved pages slightly less elegant compared to dealing with just a single file via SingleFile: when you press Ctrl + S on a page, it doesn't just save that page's HTML file but also a folder containing all of the media from the page (which, given that none of the job postings contain images, is just one more thing to have to delete).
By Ctrl-clicking on every single job posting shown behind New Posting Since Last Login (so that every new posting opens on a new tab) and then using the SingleFile extension to save the page each tab in one go (using the Save all tabs option under the SingleFile extension.), I'm able to condense the whole process of saving new postings for the day to just 1-2 minutes. Put each day's postings into a timestamped folder (made faster thanks to a handy AutoHotKey script that's always a keyboard shortcut away), which itself goes into a big folder on my local computer of all PEY job postings collected thus far, and I've got myself data on almost 2k job postings just waiting to be analyzed for some insights.
📁PEY POSTINGS ARCHIVE/├── 📁2023-09-17_20-14-10/│ ├── ...Job Postings (9_17_2023 8_13_11 PM).html│ ├── ...Job Postings (9_17_2023 8_13_12 PM).html│ └── ...├── 📁2023-09-18_00-51-40/│ ├── Job ID 43541...(9_18_2023 12_51_48 AM).html│ ├── Job ID 43554...(9_18_2023 12_52_08 AM).html│ └── ...├── 📁2023-09-18_16-08-36/├── ...└── 📁2024-05-17_16-25-26/Why not write a script to automate saving postings?
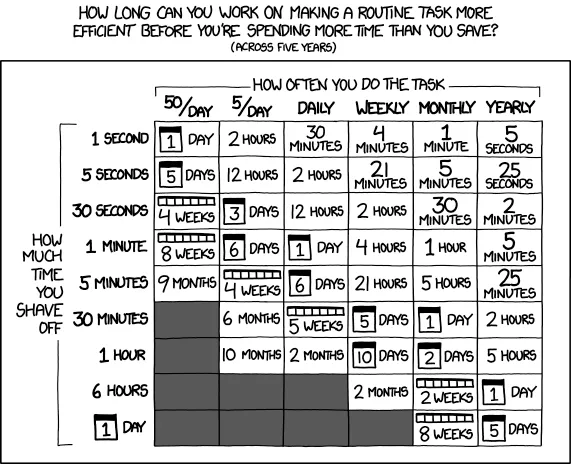

Is it possible to automate the whole process of saving data for job postings?
Technically, yes, it's absolutely feasible, but given how easy it is manually save data for job postings in a minute or two for every couple hundred of jobs (with the assistance of a few scripts to make the CTRL-clicking a lot faster), it's just not worth the time to make the routine task more efficient (I'd be spending more time than I'd save, as any XKCD reader can relate to).
Storing job postings in a database
HTML is fine for temporary storage purposes[^issok], but I need something that will allow me to view and analyze the data in a fast, efficient, and easy-to-use manner.
Enter the underrated gem of database technologies: SQLite.
[^issok]: Despite a large portion of the saved HTML files consisting of useless space in lines of JavaScript, CSS, and HTML that have nothing to do with the data that counts, it's just not worth the time investment for me to parse through every file and remove the clutter since all the saved job postings for a year only take up a couple hundred MB.
Now, I've never used SQLite before (just PostgreSQL, with a bit of Python on the side via psycopg2), but thanks to the sqlite3 documentation for Python I'm right-at-home as someone who's used psycopg2 in the past (and of course Python is ideal for the scale of data I'm working with here, just a couple thousand HTML files).
But before I can start inputting all the data into a SQLite database, I need to figure out how to extract the key information (e.g. job title, location, description, company etc.) first.
Extracting data from HTML
If it were just a single page, I could use something like Microsoft Edge's Smart Copy or the Table Capture extension and call it a day, but extracting data from >20k pages is a whole different ballgame.
The HTML code for each job posting page doesn't have the best formatting...
<!DOCTYPE html> <html lang=en dir=ltr style><!--
Page saved with SingleFile
url: https://ecc-uoft-coop-csm.symplicity.com/students/app/jobs/detail/17860b208317feac1449f4953038c9da
saved date: Mon Sep 16 2024 22:38:07 GMT-0400 (Eastern Daylight Time)
--><!--TODO LANG--><meta charset=utf-8>
<meta name=viewport content="width=device-width,initial-scale=1,minimum-scale=1">
<title>ML Developer – Software Automation & Dev Infra Intern</title>
<meta name=apple-itunes-app content="app-id=1362056979">
<meta name=google-play-app content="app-id=com.symplicity.csmandroid.es">
<style>/*!
* Bootstrap v4.1.1 (https://getbootstrap.com/)
* Copyright 2011-2018 The Bootstrap Authors
* Copyright 2011-2018 Twitter, Inc.
* Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE)
*/:root{--blue:#007bff;--indigo:#6610f2;--purple:#6f42c1;--pink:#e83e8c;--red:#dc3545;--orange:#fd7e14;--yellow:#ffc107;--green:#28a745;--teal:#20c997;--cyan:#17a2b8;--white:#fff;--gray:#6c757d;--gray-dark:#343a40;--primary:#007bff;--secondary:#6c757d;--success:#28a745;--info:#17a2b8;--warning:#ffc107;--danger:#dc3545;--light:#f8f9fa;--dark:#343a40;--breakpoint-xs:0;--breakpoint-sm:576px;--breakpoint-md:768px;--breakpoint-lg:992px;--breakpoint-xl:1200px;--font-family-sans-serif:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,sans-serif,"Apple Color Emoji","Segoe UI Emoji","Segoe UI Symbol";--font-family-monospace:SFMono-Regular,Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace}*,::after,::before{box-sizing:border-box}html{line-height:1.15;-webkit-text-size-adjust:100%;-ms-text-size-adjust:100%;-ms-overflow-style:scrollbar;-webkit-tap-highlight-color:transparent}@-ms-viewport{width:device-width}hr{overflow:visible}h1,h3{margin-top:0}p{margin-top:0}ul{margin-top:0;margin-bottom:1rem}a{-webkit-text-decoration-skip:objects}a:hover{color:#0056b3;text-decoration:underline}a:not([href]):not([tabindex]){color:inherit;text-decoration:none}a:not([href]):not([tabindex]):focus,a:not([href]):not([tabindex]):hover{color:inherit;text-decoration:none}a:not([href]):not([tabindex]):focus{outline:0}img{border-style:none}label{display:inline-block;margin-bottom:.5rem}button:focus{outline:1px dotted;outline:5px auto -webkit-focus-ring-color}button,input{font-family:inherit}input{overflow:visible}button{-webkit-appearance:button}[type=search]{outline-offset:-2px;-webkit-appearance:none}[type=search]::-webkit-search-cancel-button,[type=search]::-webkit-search-decoration{-webkit-appearance:none}::-webkit-file-upload-button{font:inherit;-webkit-appearance:button}h1,h3{margin-bottom:.5rem;color:inherit}hr{margin-top:1rem;margin-bottom:1rem;border:0;border-top:1px solid rgba(0,0,0,.1)}.container{width:100%}@media (min-width:576px){.container{max-width:540px}}@media (min-width:768px){.container{max-width:720px}}@media (min-width:992px){.container{max-width:960px}}@media (min-width:1200px){.container{max-width:1140px}}.row{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap}.col-12{position:relative;min-height:1px}.col{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1}.col-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}@media (max-width:575.98px){}@media (max-width:767.98px){}@media (max-width:991.98px){}@media (max-width:1199.98px){}@media screen and (prefers-reduced-motion:reduce){}@media (min-width:576px){}.btn{vertical-align:middle;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none;border:1px solid transparent;transition:color .15s ease-in-out,background-color .15s ease-in-out,border-color .15s ease-in-out,box-shadow .15s ease-in-out}@media screen and (prefers-reduced-motion:reduce){.btn{transition:none}}.btn:focus,.btn:hover{text-decoration:none}.btn.focus,.btn:focus{outline:0;box-shadow:0 0 0 .2rem rgba(0,123,255,.25)}.btn.disabled,.btn:disabled{opacity:.65}.btn:not(:disabled):not(.disabled){cursor:pointer}.btn:not(:disabled):not(.disabled).active,.btn:not(:disabled):not(.disabled):active{background-image:none}@media screen and (prefers-reduced-motion:reduce){}@media screen and (prefers-reduced-motion:reduce){}@media (max-width:575.98px){}@media (min-width:576px){}@media (max-width:767.98px){}@media (min-width:768px){}@media (max-width:991.98px){}@media (min-width:992px){}@media (max-width:1199.98px){}@media (min-width:1200px){}@media (min-width:576px){}@media (min-width:576px){}@media (min-width:576px){}@media (min-width:576px){}@-webkit-keyframes progress-bar-stripes{from{background-position:1rem 0}to{background-position:0 0}}@keyframes progress-bar-stripes{from{background-position:1rem 0}to{background-position:0 0}}@media screen and (prefers-reduced-motion:reduce){}@media screen and (prefers-reduced-motion:reduce){}@media (min-width:576px){}@media (min-width:992px){}@media screen and (prefers-reduced-motion:reduce){}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.carousel-item-next.carousel-item-left,.carousel-item-prev.carousel-item-right{-webkit-transform:translate3d(0,0,0);transform:translate3d(0,0,0)}}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.active.carousel-item-right,.carousel-item-next{-webkit-transform:translate3d(100%,0,0);transform:translate3d(100%,0,0)}}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.active.carousel-item-left,.carousel-item-prev{-webkit-transform:translate3d(-100%,0,0);transform:translate3d(-100%,0,0)}}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.carousel-fade .active.carousel-item-left,.carousel-fade .active.carousel-item-prev,.carousel-fade .carousel-item-next,.carousel-fade .carousel-item-prev,.carousel-fade .carousel-item.active{-webkit-transform:translate3d(0,0,0);transform:translate3d(0,0,0)}}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}.flex-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.align-self-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-end{-ms-flex-item-align:end!important;align-self:flex-end!important}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}@supports ((position:-webkit-sticky) or (position:sticky)){.sticky-top{position:-webkit-sticky;position:sticky;top:0;z-index:1020}}.sr-only{white-space:nowrap}.sr-only-focusable:active,.sr-only-focusable:focus{position:static;width:auto;height:auto;overflow:visible;clip:auto;white-space:normal}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}.text-center{text-align:center!important}@media (min-width:576px){}@media (min-width:768px){}@media (min-width:992px){}@media (min-width:1200px){}.text-capitalize{text-transform:capitalize!important}.font-weight-light{font-weight:300!important}</style>
<style>@font-face{font-family:"Roboto";font-style:italic;font-weight:100;src:url(data:font/woff2;base64,d09GMgABAAAAADnsAA4AAAAAdEwAADmTAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGoEQG6NaHJB8BmAAg0oRDAqBlnD9BwuFWgABNgIkA4swBCAFgyYHIBuSYwPucFdDbzoXjGMreBwIbotEUckJF/xlAjeGaH3AExtiRQynVZWflo42xR04ysTekpfb5qp5ZxYb4mNn4DgfNZfoae2ft3rmzO79SEFUwKSIQCXChS2xyncBQEWa8O0Znl/n+9euit7puFOVJyJGT/VkzTCMsUixSptVWWJRVv43p5Xe9n0F2gFKO3WiJQRJ343d57YpZ4Dj+C/1as/eh3BvDDdiyXLrhUKWVXbv+yGTAHgYYoZBlAS0jiiuVL4OUbRzgwN4B/T/W/vZXZv3Rlb8wH7EpP1QcUnUL0zIhEprRJoZZbNMNbe/f6vnfZTN+ufMmGMKlEQYj3pXI82O9l67Oj1o7x70uHoSGO70KOlh74wQOiLIzFoDsQwYE0WE2YfmFJLUaeaPXA4yDKLcmVOC/6/7Uv/UATp2fYCacAjGez79qoeTrStA20IBiwdlNJgKUIB3nv/+YvqO9QW/petW0d6Jwiagj83STk5NQAVUJUbBo7+c/n3HrDW1krEbMmY86uKZinP/qjAS5QkKq5bN3ldPE9WQV352dp2kFvJs/2dFSg6jT0icRUmcBmqrMKslO5/sQzreIHLm9v+fO7G9p32fRYIEGyRIkEHcbd//XXSzQAQ8qVjGv8sfQ7XdbLp/PD8ggvZdh4AhAuB5mr8kAxBzASBZXxVSqEKKVUiZCqmgqFVqHo1GreAmHAKz6jzIlQiCsid6oJgnBjRMBa7k5+PCZWnNMASjkTSRZtJy8yDAuVQYQDzwwXZuQODZWcmxFnp+Mjcm9JLg1PgDQAAcryVe/NzkeIAB1LUDAQYY52XCgi0nCOD07WdDCJ9b70uN6Jd5ZY+6RLo/1O2vs3YNeZ938Y7TF3C/A/3NgHGvZTv5GTDPN5Hy0z4O9IFR0mdc5ieIzPGr53Zk3aYnNqtUtmu+waF1uWv3nxsH/2Sf97sDS/ngfpbuvza6/2KMudZ2FBc9pJYqOOTvJ83fyPO8y...
...
......but thanks to everything being stored in tables I can just use Python's trusty BeautifulSoup4 library on my locally saved HTML pages and get the text in every table data cell in less than 50 lines of code:
import argparsefrom bs4 import BeautifulSoup
def parse_html_file(filepath, verbose=False): with open(filepath, 'r', encoding='utf-8') as file: html_content = file.read()
soup = BeautifulSoup(html_content, 'lxml')
data = {} rows = soup.find_all('tr') ## find all table rows
for row in rows: tds = row.find_all('td') ## find all table data cells
if len(tds) >= 2: label_td = tds[0] label_text = '\n'.join(label_td.stripped_strings)
value_td = tds[1] value_text = '\n'.join(value_td.stripped_strings)
data[label_text] = value_text
if verbose: for key, value in data.items(): print(f"{key}: {value}") else: print("Parsing completed.")
if __name__ == "__main__": parser = argparse.ArgumentParser(description="Parse HTML for 2 column table data.") parser.add_argument("-f", "--filepath", required=True, help="Path to the HTML file to be parsed.") parser.add_argument("-v", "--verbose", action="store_true", help="Print parsed data.")
args = parser.parse_args() parse_html_file(args.filepath, args.verbose)Trying out the quickly-written parse.py script on one of the saved HTML pages, and it's able to get all of the values for all of the table fields with no issues:
python parse.py --verbose --filepath "Job ID 43628....html"Position Type:: Professional Experience Year Co-op (PEY Co-op: 12-16 months)Job Title:: ML Developer - Software Automation & Developer InfrastructureJob Location:: TorontoJob Location Type:: FlexibleIf working on site, can you provide a copy of your COVID-19 safety protocols?:: NoNumber of Positions:: 1Salary:: $42.00 hourly for 40.0 hours per weekStart Date:: 05/06/2024End Date:: 04/25/2025Job Function:: Information Technology (IT)Job Description:: Cerebras Systems has pioneered a groundbreaking chip and system that revolutionizes deep learning applications. Our system empowers ML researchers to achieve unprecedented speeds in training and inference workloads, propelling AI innovation to new horizons.The Condor Galaxy 1 (CG-1), unveiled in a recent announcement, stands as a testament to Cerebras' commitment to pushing the boundaries of AI computing. With a staggering 4 ExaFLOP processing power, 54 million cores, and 64-node architecture, the CG-1 is the first of nine powerful supercomputers to be built and operated through an exclusive partnership between Cerebras and G42. This strategic collaboration aims to redefine the possibilities of AI by creating a network of interconnected supercomputers that will collectively deliver a mind-boggling 36 ExaFLOPS of AI compute power upon completion in 2024.Cerebras is building a team of exceptional people to work together on big problems. Join us!.About The RoleAs a Machine Developer - Software Automation & Developer Infrastructure Engineer, you will use your knowledge of testing and testability to influence better software design, promote proper engineering practice, bug prevention strategies, testability, scalability, and other advanced quality concepts. The position will play a huge role in the quality of Cerebras software. We are looking for engineers that have a broad set of technical skills and who are ready to tackle the biggest at-scale problems in HW-based deep learning accelerators.ResponsibilitiesWrite scripts to automate testing and create tools to allow easy development of software regression testsHelp identify weak spots and potential customer pain points and drive the software organization towards customer focused quality metricsImplement creative ways to break software and identify potential problemsContribute to developing requirements specifications with a focus on developing verification testsJob Requirements:: RequirementsEnrolled within University of Toronto's PEY program with a degree in Computer Science, Computer Engineering, or any other related disciplineExperience in developing automated tests for compute/machine learning or networking systems within a large-scale enterprise environmentAbility to take responsibility for monitoring product development and usage at all levels with an end goal toward improving product qualityStrong knowledge of software system design, C++ and PythonPreferredStrong software testing experience with a proven track record in scaling highly technical teamsKnowledge of UNIX/Linux and Windows environmentsKnowledge of neural network architecture and ML/AI deep learning principlesPrior experience in designing and developing test automation for HW systems involving ASICs or FPGAsPrior experience working with live hardware systems and debug tools operating in a real time environment such as networking devices or live computing systemsPreferred Disciplines:: Computer EngineeringComputer ScienceEngineering Science (Electrical and Computer)Engineering Science (Infrastructure)Engineering Science (Machine Intelligence)Engineering Science (Robotics)All Co-op programs:: NoTargeted Co-op Programs:: Targeted ProgramsProfessional Experience Year Co-op (12 - 16 months)Application Deadline:: Nov 1, 2023 11:59 PMApplication Receipt Procedure:: Online via systemIf by Website, go to:: https://www.cerebras.net/careers/?gh_jid=5321500003Additional Application Information:: Please apply withboth resume & transcript.Lacking transcript will disqualify you from being considered.Note that applications will be considered on a rolling basis. Apply as early as possible.Note to PEY Co-op applicants: In addition to your application by email/website, please ensure that you select the “I intend to apply for this position” tab on the portal. This will give us a record of your submitted application in the event that you will be invited for interviews.U of T Job Coordinator:: Yasmine AbdelhadyOrganization:: Cerebras SystemsDivision:: Computer ScienceWebsite:: https://cerebras.net/Length of Workterm:: FLEXIBLE PEY Co-op: 12-16 months (range)Finetuning data extraction
There's a few nuances to the data extraction that mean this simple script needs just a bit more extending so it can properly parse the entire dataset.
I'm getting the text corresponding to any inline links, but the links themselves aren't included since they're within the html <a> tags, so I need to add handling for those as well. Another nuance is the fact that the formatting for HTML pages has changed[^attimes] (several times actually) over the course of the last two semesters.
Since the location of the data has always remained in tables, that's largely a non-issue. While the job title and company name included in the header above any table on job posting pages are currently missed by the script, that data is also present in the tables below (and extracted by the script properly), so that, too, is a non-issue.
With one exception: job IDs aren't extracted.
Luckily, I had the foresight to configure SingleFile to include the job ID automatically as part of the filename for each HTML page back when I started the archival process, so I can add some logic to parse that as well. Unluckily, however, there were a few periods of time where that configuration was lost[^eglost], so I'm going to have to do some file contents parsing regardless.
[^eglost]: At one point, all of my extensions were uninstalled somehow (probably due to a Chrome update gone wrong), and so I had forgotten to reconfigure SingleFile to include job IDs in the saved filenames for many ways until I got some free time and was able to pore over my notes (and reconfigure everything back to the way it was).
[^attimes]: At times purposefully by myself (e.g. adding Job ID and later Job Title to filenames for saved HTML files for easier file browsing and duplication checking), and at times by the university (i.e. there was a big redesign of the job board that took place in the latter half of the fall semester, which made it so the PEY job board uses the same frontend design as job boards on CLNx, whereas prior to that it looked a bit different despite functionally working the same).
A quick manual parsing of the different HTML files shows that there's only two different locations that job IDs can be located (one for the old design, and the other for the new design), so I can just add another function to try and find the job ID located at either location in all files and I'm now able to extract all the job IDs as well:
import argparsefrom bs4 import BeautifulSoupimport re
def extract_job_id_from_html(soup): ## try to find job ID in a <h1> tag with the specific class
header_tag = soup.find('h1', class_='h3 dashboard-header__profile-information-name mobile--small-font color--font--white margin--b--s') if header_tag: header_text = header_tag.get_text(strip=True) match = re.match(r'^(\d+)', header_text) if match: return match.group(1)
## if not found, try to find an <h1> tag containing the words "Job ID" job_id_tag = soup.find('h1', string=re.compile(r'Job ID', re.IGNORECASE)) if job_id_tag: job_id_text = job_id_tag.get_text(strip=True) match = re.search(r'Job ID\s*:\s*(\d+)', job_id_text, re.IGNORECASE) if match: return match.group(1)
return None
def parse_html_file(filepath, verbose=False): with open(filepath, 'r', encoding='utf-8') as file: html_content = file.read()
36 collapsed lines
soup = BeautifulSoup(html_content, 'lxml')
data = {} job_id = extract_job_id_from_html(soup) if job_id: data['Job ID'] = job_id
rows = soup.find_all('tr') ## find all table rows
for row in rows: tds = row.find_all('td') ## find all table data cells
if len(tds) >= 2: label_td = tds[0] label_text = '\n'.join(label_td.stripped_strings)
value_td = tds[1] value_text = '\n'.join(value_td.stripped_strings)
data[label_text] = value_text
return data
if __name__ == "__main__": parser = argparse.ArgumentParser(description="Parse HTML for 2 column table data.") parser.add_argument("-f", "--filepath", required=True, help="Path to the HTML file to be parsed.") parser.add_argument("-v", "--verbose", action="store_true", help="Print parsed data.")
args = parser.parse_args() data = parse_html_file(args.filepath, args.verbose)
if args.verbose: for key, value in data.items(): print(f"{key}: {value}") else: print("Parsing completed.")Now with a method of easily extracting all the relevant data from each HTML page, all that's left is to automate running the parser across all files saved within timestamped subdirectories on my local computer and pipe the data into a SQLite DB.
Storing data in SQLite
Why SQLite?
SQLite sits right there in the sweet middle spot between raw data formats (like CSV, JSON) that are good fits for simple data (e.g. temperature, word lists) but aren't as great for larger datasets with more complexity (especially when it comes to data analysis) and other larger RDBMS (relational database management system) libraries that might be better designed for scaleability but are really just overkill for the little pet project that I have here at hand.
And the fact that SQLite is a single file on disk means that sharing the finely extracted and processed data is a lot easier too, which is important for me because I want future PEY co-op students to learn what they can from the dataset and better set their expectations for what to expect from program (and I hope the data helps prospective UofT students better make their admission decisions as well).
Most importantly, SQLite is serverless (unlike PostgreSQL or MySQL), which saves me a lot of headache and setup for this relatively small-scale project (especially since sqlite3 is built into Python's standard library!).
Pipelining data from ~2k HTML files to a single SQLite DB
Using SQLite with Python via sqlite3 is simple enough. All I need to do is add some additional code for extracting the job posting date from the parent folder for each job posting's HTML page and for iterating across every subfolder for PEY job postings on my local computer, as well as draft up a schema for the SQLite DB and write some code for piping data from Python dictionaries to the DB file.
Database Schema
Thankfully, all job postings share largely the same fields, so (for the time being) the schema just ends up being an amalgamation of all the relevant table fields.
One small slight is that Application Receipt Procedure and Application Method are often used interchangeably (Application Receipt Procedure largely before the redesign, and Application Method after), and when one field is used the other is usually left blank (except for some positions which use both, meaning that I can't exactly combine them into a single field without losing data; e.g. sometimes Application Method for a posting states to use the built-in applicant tracking system while Application Receipt Procedure states to use some company link, which is likely just attributable to job posters sticking with the default options when creating a new post). It's largely a non-issue, and after some further exploration into the specific overlapping data I should be able to easily combine both into a single field.
I could potentially extend the schema with functional dependencies for repetitive data like company names, although it's really only company and maybe a few other fields where values are guaranteed to repeat (Job Location Type, Salary, etc. can vary wildly and use combinations of text or integers, so there's not much we can do to unify them) so it's not the best representation for a general-purpose database (lossy conversions can always be made for analysis).
Regardless, I can update the previous python file used for parsing to handle the new SQLite schema easily enough:
...def store_data_in_db(data, db_cursor): columns = ', '.join([f'"{key}"' for key in data.keys()]) placeholders = ', '.join(['?' for _ in data.values()]) sql = f'INSERT INTO "JobPosting" ({columns}) VALUES ({placeholders})' try: db_cursor.execute(sql, tuple(data.values())) except sqlite3.IntegrityError: logging.info("Integrity Error: Skipping row") pass
def create_db_schema(db_cursor): db_cursor.execute(''' CREATE TABLE IF NOT EXISTS JobPosting ( id INTEGER, postingDate DATE, title TEXT, company TEXT, companyDivision TEXT, companyWebsite TEXT, location TEXT, locationType TEXT, numPositions INTEGER, salary TEXT, startDate TEXT, endDate TEXT, function TEXT, description TEXT, requirements TEXT, preferredDisciplines TEXT, applicationDeadline TEXT, applicationMethod TEXT, applicationReceiptProcedure TEXT, applicationDetails TEXT, PRIMARY KEY(id, postingDate) ) ''')
if __name__ == "__main__": ...Parsing to .db
Finally, with some additional code for properly parsing through all subfolders in my local directory and setting the postingDate value based on the folder name[^timestamped] for each file, I can transform the entire dataset of >1.8k job postings into a single .db file under 10MB in size in ~3 min (which might've taken even less time if it weren't running on an old spinning hard drive).
import argparsefrom bs4 import BeautifulSoupimport reimport osimport sqlite3from tqdm import tqdmimport logging
def extract_job_id_from_html(soup): ## Try to find job ID in a <h1> tag with the specific class header_tag = soup.find('h1', class_='h3 dashboard-header__profile-information-name mobile--small-font color--font--white margin--b--s') if header_tag: header_text = header_tag.get_text(strip=True) match = re.match(r'^(\d+)', header_text) if match: return match.group(1)
## If not found, try to find an <h1> tag containing the words "Job ID" job_id_tag = soup.find('h1', string=re.compile(r'Job ID', re.IGNORECASE)) if job_id_tag: job_id_text = job_id_tag.get_text(strip=True) match = re.search(r'Job ID\s*:\s*(\d+)', job_id_text, re.IGNORECASE) if match: return match.group(1)
return None
def parse_html_file(filepath, job_posting_date, verbose=False): with open(filepath, 'r', encoding='utf-8') as file: html_content = file.read()
soup = BeautifulSoup(html_content, 'lxml')
## Extract the year, month, and day from the job_posting_date string posting_date = job_posting_date.split('_')[0] data = {'postingDate': posting_date} job_id = extract_job_id_from_html(soup) if job_id: data['id'] = job_id
rows = soup.find_all('tr') ## find all table rows
for row in rows: tds = row.find_all('td') ## find all table data cells
if len(tds) >= 2: label_td = tds[0] label_text = '\n'.join(label_td.stripped_strings).replace(':', '')
value_td = tds[1] value_text = '\n'.join(value_td.stripped_strings)
links = value_td.find_all('a') for link in links: url = link.get('href') link_text = link.get_text() value_text = value_text.replace(link_text, f'{link_text} ({url})')
## Map label_text to corresponding database column column_mapping = { ## 'Job ID': 'id', ## 'Job Posting Date': 'postingDate', 'Job Title': 'title', 'Organization': 'company', 'Division': 'companyDivision', 'Website': 'companyWebsite', 'Job Location': 'location', 'Job Location Type': 'locationType', 'Number of Positions': 'numPositions', 'Salary': 'salary', 'Start Date': 'startDate', 'End Date': 'endDate', 'Job Function': 'function', 'Job Description': 'description', 'Job Requirements': 'requirements', 'Preferred Disciplines': 'preferredDisciplines', 'Application Deadline': 'applicationDeadline', 'Application Method': 'applicationMethod', 'Application Receipt Procedure': 'applicationReceiptProcedure', 'If by Website, go to': 'applicationReceiptProcedure', 'Additional Application Information': 'applicationDetails', }
## Check if label_text matches any of the predefined columns if label_text in column_mapping: db_column = column_mapping[label_text] ## If key already exists, append the value to it if db_column in data: data[db_column] += f'\n{value_text}' else: data[db_column] = value_text
return data
def store_data_in_db(data, db_cursor): columns = ', '.join([f'"{key}"' for key in data.keys()]) placeholders = ', '.join(['?' for _ in data.values()]) sql = f'INSERT INTO "JobPosting" ({columns}) VALUES ({placeholders})' try: db_cursor.execute(sql, tuple(data.values())) except sqlite3.IntegrityError: logging.info("Integrity Error: Skipping row") pass
def create_db_schema(db_cursor): db_cursor.execute(''' CREATE TABLE IF NOT EXISTS JobPosting ( id INTEGER, postingDate DATE, title TEXT, company TEXT, companyDivision TEXT, companyWebsite TEXT, location TEXT, locationType TEXT, numPositions INTEGER, salary TEXT, startDate TEXT, endDate TEXT, function TEXT, description TEXT, requirements TEXT, preferredDisciplines TEXT, applicationDeadline TEXT, applicationMethod TEXT, applicationReceiptProcedure TEXT, applicationDetails TEXT, PRIMARY KEY(id, postingDate) ) ''')
if __name__ == "__main__": logging.basicConfig(filename='run.log', level=logging.INFO, format='%(asctime)s %(message)s')
parser = argparse.ArgumentParser(description="Parse HTML files in a folder and store data in SQLite DB.") parser.add_argument("-d", "--directory", default=os.getcwd(), help="Path to the directory containing HTML files. Default is the current directory.") parser.add_argument("--db", default=os.path.join(os.getcwd(), "job_postings.db"), help="SQLite database file to store the parsed data. Default is 'job_postings.db' in the directory specified by -d.") parser.add_argument("-v", "--verbose", action="store_true", help="logging.info parsed data.")
args = parser.parse_args()
conn = sqlite3.connect(args.db) cursor = conn.cursor() create_db_schema(cursor)
## Get the list of files files = [os.path.join(dirpath, file) for dirpath, _, files in os.walk(args.directory) for file in files if file.endswith('.html') or file.endswith('.htm')]
## Create a progress bar with tqdm(total=len(files)) as pbar: for subdir, _, files in os.walk(args.directory): job_posting_date = os.path.basename(subdir) for file in files: if file.endswith('.html') or file.endswith('.htm'): filepath = os.path.join(subdir, file) logging.info(filepath) data = parse_html_file(filepath, job_posting_date, args.verbose) store_data_in_db(data, cursor) ## Update the progress bar pbar.update(1)
conn.commit() conn.close() logging.info("Parsing and storing completed.")[^timestamped]: e.g. 📁2023-09-17_20-14-10; easily achievable thanks to github.com/sadmanca/ahk-scripts/blob/master/keys.ahk
Viewing the data
And so we have it: a single database file storing every single job posted on the UofT PEY Co-op job board for 2T5s[^2t5] (from 2023 to 2024). You can take a look at some of the results from querying the data below[^anotebaout], or download the SQLite .db file from the latest release at github.com/sadmanca/uoft-pey-coop-job-postings.
[^2t5]: UofT Engineering students and alumni often include their graduation year after their name to denote their class. If you start first year in 2021, you will be part of the class of 2025, denoted as “2T5” (pronounced “two-tee-five”).
[^anotebaout]: I've built-in a SQL view called JobPostings (the table with the actual data is called JobPosting, without the "s") that excludes some of the columns with very long values (e.g. description, requirements, preferredDisciplines, applicationDetails) to make table formatting look a bit better if you're running SELECT * queries. To run queries with the excluded columns, use the JobPosting table instead.
Sample Queries
Which companies posted the most number of jobs?
SELECT company, COUNT(*) as num_postingsFROM JobPostingGROUP BY companyORDER BY num_postings DESC;| Company | Num Postings | |-----------------------------------------------------------|--------------| | Sanofi Canada | 92 | | Celestica Inc. | 74 | | Hydro One | 62 | | Huawei Technologies Canada Co.,Ltd. | 47 | | Pulsenics Inc | 35 | | Airbus | 31 | | RAISE (Ian Martin Group) on behalf of Enbridge | 30 | | Geotab | 30 | | The Independent Electricity System Operator (IESO) | 26 | | SOTI Inc. | 25 | | Ericsson | 23 | | STEMCELL Technologies | 22 | | Isowater Corporation | 22 | | Toronto Hydro | 20 | | Veoneer Canada Inc. (Formerly Autoliv) | 18 | | AMD (Advanced Micro Devices, Inc.) | 18 | | The Six Semiconductor | 17 | | Cenovus | 17 | | Qualcomm Canada Inc. | 15 | | Prep Doctors | 14 | | Kepler Communications | 13 | | Evertz Microsystems Ltd | 13 | | Agnico Eagle Mines Ltd. | 13 | | Xero | 12 | | Untether AI | 12 | | National Research Council Canada | 12 | | Bombardier Aerospace | 12 | | AlphaWave SEMI | 12 | | Vale Canada | 11 | | Questrade | 11 | | Paradigm Electronics Inc. | 11 | | Lincoln Electric Company of Canada | 11 | | IBI Group | 11 | | FGF Brands | 11 | | Environment and Climate Change Canada | 11 | | City of Toronto | 11 | | Atlantic Packaging Products Ltd. | 11 | | Acciona Infrastructure Canada Inc. | 11 | | ecobee | 10 | | SAFRAN Landing Systems (Messier-Dowty Inc.) | 10 | | IKO Industries | 10 | | Ceridian | 10 | | Synopsys | 9 | | NETINT Technologies Inc. | 9 | | MHIRJ Aviation Group | 9 | | Litens Automotive Group | 9 | | Kinectrics Inc. | 9 | | Collins Aerospace | 9 | | Cerebras Systems | 9 | | Canadian Natural Resources Limited | 9 | | Brigham & Women's Hospital, Harvard Medical School | 9 | | York Region | 8 | | Toronto Transit Commission (TTC) | 8 | | Tenstorrent Inc | 8 | | Honda of Canada Mfg | 8 | | Stackpole International | 7 | | EllisDon | 7 | | Aecon Group Inc. | 7 | | eCAMION | 6 | | Thermo Fisher Scientific | 6 | | Royal Canadian Mounted Police (RCMP) | 6 | | Powersmiths International Corp. | 6 | | Ontario Clean Water Agency (OCWA) | 6 | | Northbridge Financial | 6 | | NVIDIA | 6 | | NOVA Chemicals | 6 | | Mondelez International | 6 | | Ministry of Transportation | 6 | | Mattamy Homes Ltd. | 6 | | Marvell Technology Group (US) | 6 | | Martinrea International Inc | 6 | | Ledcor | 6 | | Kingston Midstream | 6 | | Global Affairs Canada | 6 | | Genesys Canada Laboratories Inc. (Genesys) | 6 | | ExxonMobil Canada | 6 | | Amazon | 6 | | Welbilt | 5 | | WSP Canada Inc. | 5 | | Suncor Energy | 5 | | Smith + Andersen | 5 | | Purpose Building Inc. | 5 | | Ontario Teachers Pension Plan (OTPP) | 5 | | Mold-Masters Limited | 5 | | Mission Control Space Services | 5 | | Ministry of the Environment, Conservation and Parks | 5 | | Microchip Technology | 5 | | Jaguar Land Rover Canada | 5 | | Husky Injection Molding Systems Ltd. | 5 | | Colortech Inc. | 5 | | BBA | 5 | | Astera Labs | 5 | | Arxtron Technologies | 5 | | Air Canada | 5 | | eShipper | 4 | | e-Zinc Inc | 4 | | Zynga | 4 | | WOLF Advanced Technology | 4 | | VPC Group Inc. | 4 | | University of Toronto - Facilities & Services | 4 | | The Travel Corporation | 4 | | Tesla Motors | 4 | | Synaptive Medical Inc. | 4 | | Solvay Inc | 4 | | Scotiabank | 4 | | Purolator Inc. | 4 | | Petro Canada Lubricants (Hollyfrontier) | 4 | | Peel Plastic Products Limited | 4 | | PICCO Group of Companies | 4 | | Ministry of Children, Youth, and Social Services | 4 | | KAPP Infrastructure Inc. | 4 | | Intersect Power | 4 | | Intel Canada | 4 | | Grounded Engineering | 4 | | GHD | 4 | | CGI Group Inc. | 4 | | Bronte Construction | 4 | | Bayer Healthcare | 4 | | Alectra Utilities | 4 | | Zebra Technologies | 3 | | Viavi Solutions | 3 | | Umicore Autocat Canada Corp | 3 | | Uken Games | 3 | | Tencent Technology Company | 3 | | TYLin | 3 | | Seismic Software, Inc. | 3 | | Region of Peel | 3 | | Region of Durham | 3 | | Pulsenics | 3 | | Perpetua | 3 | | Nfinite Nanotechnology | 3 | | Nanoleaf | 3 | | Movellus | 3 | | Mother Parker's Tea and Coffee | 3 | | Ministry of Health and Long-Term Care | 3 | | Magna International | 3 | | MDA | 3 | | Lumentum Inc. | 3 | | LEA Consulting Ltd. | 3 | | Kernal Biologics, Inc. | 3 | | InteraXon Inc | 3 | | Halton Region | 3 | | Green Infrastructure Partners Inc | 3 | | GGY a Moodys Analytics Company | 3 | | FedEx Ground | 3 | | FedEx Express Canada | 3 | | Eastern Power Limited | 3 | | Dynasty Power | 3 | | Deighton Associates Ltd. | 3 | | Defence Research and Development Canada | 3 | | Defence R&D Canada (DRDC) - Ottawa | 3 | | Circle Cardiovascular Imaging Inc. | 3 | | Ciena | 3 | | Cadence Design Systems Inc | 3 | | CES Transformers | 3 | | C. F. Crozier & Associates | 3 | | Boston Scientific | 3 | | Boeing | 3 | | Arctic Wolf Networks | 3 | | Aercoustics Engineering Limited | 3 | | AYOS Designs | 3 | | AGS Automotive Systems | 3 | | Zaber Technologies | 2 | | Xpan Inc. | 2 | | WalterFedy | 2 | | Volta Energy | 2 | | Veeva Systems | 2 | | Varicent | 2 | | Vale | 2 | | Urbantech Consulting | 2 | | University of Toronto - ITS Enterprise Applications and Solutions Integration | 2 | | University of Toronto | 2 | | Turnkey Modular Systems Inc | 2 | | Thornhill Medical | 2 | | Thales Canada | 2 | | Terrestrial Energy | 2 | | TC Energy (formerly TransCanada) | 2 | | Synergy Partners | 2 | | Stryker | 2 | | Structura Biotechnology Inc. | 2 | | StratumAI | 2 | | StoneX Group Inc. | 2 | | Square | 2 | | Spring Air Systems Inc. | 2 | | SparkLease Inc | 2 | | Snowflake | 2 | | Smarter Alloys | 2 | | SmartTrade Technologies | 2 | | SickKids | 2 | | Shell Canada Limited | 2 | | Safuture Inc. | 2 | | Royal Bank of Canada (RBC) | 2 | | Read Jones Christoffersen (RJC Engineers) | 2 | | Rapyuta Robotics Co., Ltd. (SWITZERLAND) | 2 | | Rakuten Kobo Inc. | 2 | | RBC Capital Markets | 2 | | Quantum Lifecycle Partners LP | 2 | | Quanta Technology | 2 | | Qualitrol Corp | 2 | | Overbond | 2 | | Nuclear Waste Management Organization | 2 | | Next Hydrogen Corporation (NHC) | 2 | | Mokal Industries | 2 | | ModiFace | 2 | | Modern Niagara Group Inc. | 2 | | Magna | 2 | | Lobo Consulting Services Inc. | 2 | | Liburdi Turbine Services | 2 | | Lanxess | 2 | | Lake Harbour Co Ltd | 2 | | Kijiji | 2 | | KGHM International LTD. | 2 | | Jamieson Wellness Inc. | 2 | | Intel Corporation | 2 | | Inoki | 2 | | Indigenous Services Canada | 2 | | Indie Semiconductor | 2 | | Hungerford Consulting Ltd. | 2 | | Health Canada | 2 | | Hatch Ltd. | 2 | | Harmonic Fund Services | 2 | | Hanon Systems EFP Canada Ltd. (Formerly Magna) | 2 | | HBNG Holborn Group | 2 | | Groq Inc. | 2 | | Griffith Foods Ltd. | 2 | | Grascan Construction Ltd. | 2 | | G&W Canada Corporation | 2 | | Faire | 2 | | Evoco Ltd | 2 | | Empire Life | 2 | | Electrovaya Corp. | 2 | | EHV Power | 2 | | Dragados Canada | 2 | | Deep Genomics | 2 | | Continuous Colour Coat Limited | 2 | | Coltene SciCan | 2 | | City of Mississauga | 2 | | Chatsimple | 2 | | ChargeLab Inc | 2 | | CentML Inc | 2 | | Canadian Tire Corporation | 2 | | Canadian Nuclear Safety Commission | 2 | | Canadensys Aerospace | 2 | | Cadillac Fairview | 2 | | CIMCO Refrigeration | 2 | | CERT Systems Inc. | 2 | | British Columbia Investment Management Corp | 2 | | BlueRock Theraputics | 2 | | Bloom AI | 2 | | Berg Chilling Systems | 2 | | Bank of Montreal (BMO) | 2 | | Bank of America Merrill Lynch | 2 | | BMO Financial Group | 2 | | Astro Shoring | 2 | | Arup | 2 | | Arctic Canadian Diamond Company Ltd. | 2 | | Aqusense | 2 | | Alta Planning + Design Canada, Inc. | 2 | | ACS Powersports | 2 | | iManage | 1 | | ePIC Blockchain Technologies | 1 | | Zomp Inc. | 1 | | ZS Associates | 1 | | YScope Inc | 1 | | Wolfe Heavy Equipment | 1 | | Walmart Canada | 1 | | Wakefield Canada - Castrol | 1 | | Volvo Cars | 1 | | Vivid Machines | 1 | | Vexos | 1 | | Veolia Water Technologies & Solutions | 1 | | Upstream Works Software | 1 | | Upper Canada Consultant | 1 | | University of Toronto Scarborough Campus | 1 | | UT Elevator (NA) Inc. | 1 | | UHN- (Princess Margaret, Toronto General, Toronto Western, Toronto Rehab) | 1 | | Tridel | 1 | | Trexo Robotics | 1 | | Trend Micro Canada Technologies Inc. | 1 | | Tractel Ltd | 1 | | Toyota | 1 | | Town of Oakville | 1 | | Thomson Reuters | 1 | | Third Rails Ltd | 1 | | The Poirier Group | 1 | | The Napoleon Group of Companies | 1 | | The Miller Group | 1 | | The Master Group | 1 | | Tetra Trust | 1 | | Tetra Tech | 1 | | Tersa Earth Innovations | 1 | | Tenaris Shawcor | 1 | | Teck Resources Ltd. | 1 | | Technical University of Munich (TUM) | 1 | | TD Securities | 1 | | Synopsys Inc | 1 | | Sun Life Financial | 1 | | Stelco | 1 | | Stantec Consulting Ltd. | 1 | | Sowingo | 1 | | SnapWrite | 1 | | Slate Technologies Canada Limited | 1 | | Simpplr | 1 | | Signal 1 | 1 | | Siemens Canada Limited | 1 | | Semtech | 1 | | Select Equity Group, L.P. | 1 | | Salytics | 1 | | Safety Power Inc | 1 | | SRK Consulting (Canada) Inc. | 1 | | SNC-Lavalin | 1 | | SLR Consulting (Canada) Ltd. | 1 | | SGS Canada Inc | 1 | | S&C Electric Canada Ltd. | 1 | | RxFood | 1 | | Rockwool | 1 | | RocMar Engineering Inc. | 1 | | Ripple Therapeutics | 1 | | Reinsurance Management Associates | 1 | | Regional Municipality of York (York Region) | 1 | | QMC Metering Solutions | 1 | | Public Services and Procurement Canada | 1 | | Providence Therapeutics | 1 | | Procter & Gamble (P&G) | 1 | | ProAutomated | 1 | | Princess Margaret Cancer Centre, University Health Network | 1 | | Pratt & Whitney Canada Inc. | 1 | | Powertech Labs Inc. | 1 | | Power Advisory | 1 | | Posterity Group | 1 | | Pomerleau, Inc | 1 | | PointClickCare | 1 | | Pinchin Ltd. | 1 | | PepsiCo | 1 | | Pelicargo | 1 | | PartnerRe Life Reinsurance Company of Canada | 1 | | Parsons Inc. | 1 | | Parametric Research Labs Inc. | 1 | | Pani Energy | 1 | | Ovintiv | 1 | | Ontario Transit Group | 1 | | Ontario Public Service | 1 | | Ontario Ministry of Transportation | 1 | | OPTrust | 1 | | ONIT Energy Ltd | 1 | | Nutrien | 1 | | Nuclear Promise X Inc. | 1 | | Nojumi Solutions Inc. | 1 | | New School Foods Inc. | 1 | | NAPCO, Royal Pipe & Fittings | 1 | | Modern Niagara | 1 | | Micrometric Jig Boring & Jig Grinding Ltd. | 1 | | Metro Inc. | 1 | | Metric Contracting Service Corporation | 1 | | Mesosil | 1 | | McCain Foods | 1 | | Mars Canada Inc. | 1 | | Manulife Financial | 1 | | Manulife | 1 | | Mancor Industries | 1 | | Lumerate | 1 | | Loblaw Companies Limited | 1 | | Lactalis Canada | 1 | | Konrad Group | 1 | | Kinross Gold Corporation | 1 | | Kiewit | 1 |
Where are most jobs located?
SELECT location, COUNT(*) as num_postingsFROM JobPostingGROUP BY locationORDER BY num_postings DESC;| Location | Num Postings | |--------------------------------------------------------------------------|--------------| | Toronto | 295 | | Toronto, ON | 168 | | Mississauga, ON | 73 | | Mississauga | 55 | | Markham, Ontario | 52 | | Oakville, ON | 38 | | Ottawa, ON | 35 | | Mirabel, Quebec | 31 | | Markham | 27 | | Vancouver, BC | 25 | | North York, ON | 20 | | Toronto, ON, CA | 18 | | Owen Sound | 18 | | Ottawa | 18 | | Oakville | 18 | | 7455 Birchmount Rd, Markham, ON L3R 5C2, Canada | 18 | | Markham, ON | 17 | | Main Office (Markham, ON) | 17 | | Connaught Campus, 1755 Steeles Avenue West, Toronto, ON, Canada, M2R 3T4 | 17 | | Brampton | 17 | | Toronto, Ontario | 15 | | Mississauga, Ontario | 15 | | Vaughan | 14 | | Brampton, ON | 13 | | Burlington | 12 | | Etobicoke | 11 | | 1755 Steeles Avenue West, Toronto, ON, Canada, M2R 3T4 | 11 | | Markham, Ontario, Canada | 10 | | Calgary | 10 | | Scarborough | 9 | | Whitby | 8 | | Remote | 8 | | Etobicoke, Ontario | 8 | | Concord, Ontario | 8 | | Canada | 8 | | Rankin Inlet, Nunavut | 7 | | Newmarket | 7 | | | 7 | | Woodbridge | 6 | | Remote / Toronto | 6 | | North York | 6 | | Newmarket, Ontario | 6 | | National Capital Region, Ottawa | 6 | | Estevan, SK | 6 | | Concord, ON | 6 | | Calgary, Alberta | 6 | | Calgary, AB - Head Office or Fort McMurray, AB ? Horizon and Albian Mine Site | 6 | | Alliston, Ontario | 6 | | Ajax, ON | 6 | | 1755 Steeles Avenue West, Toronto, ON | 6 | | Ottawa, Ontario | 5 | | Ontario | 5 | | Lloydminster, SK | 5 | | Joffre, AB | 5 | | Cambridge, Massachusetts, USA | 5 | | Calgary, AB | 5 | | CA-AB-Calgary | 5 | | 240 Richmond Street West Toronto, ON, Canada, M5V 1V6 | 5 | | Waterloo | 4 | | Toronto, Canada | 4 | | Newmarket, ON | 4 | | Mississauga, ON, CA | 4 | | Markham, Canada | 4 | | Collingwood | 4 | | Bolton, ON | 4 | | AI CENTRE of EXCELLENCE (Digital Data Hub), 240 Richmond Street West Toronto, ON, Canada, M5V 1V6 | 4 | | 49 Rutherford Rd, Brampton | 4 | | 3966 JinDu Rd., Shanghai | 4 | | 2430 Royal Windsor Drive, Mississauga, Ontario | 4 | | 196 Spadina Ave, Toronto ON | 4 | | 1890 Alstep Dr, Mississauga, ON L5S 1W1 | 4 | | 175 Mostar Street, Suite 200, Stouffville, Ontario | 4 | | 175 Galaxy Blvd., Toronto, ON | 4 | | 1 Commerce Valley Dr E, Thornhill, ON L3T 7X6 | 4 | | Winnipeg, MB | 3 | | Whitby/Scarborough | 3 | | Vaughan, ON | 3 | | Vancouver | 3 | | Toronto, Ontario, CA | 3 | | Toronto, ON, Canada | 3 | | Toronto or Thornhill | 3 | | Sudbury | 3 | | St. George (downtown Toronto) | 3 | | Sarnia, Ontario | 3 | | Mississauga, 2100 Meadowvale Blvd. (Hwy 401/Mississauga Rd) | 3 | | Fargo, North Dakota | 3 | | Downtown Toronto | 3 | | Chatham, ON | 3 | | Cambridge, MA (USA) | 3 | | Burlington, On | 3 | | Burlington, ON | 3 | | Brampton, ON (87 Orenda Road) | 3 | | Beijing, China | 3 | | Barrie, ON | 3 | | Baker Lake or Rankin Inlet, Nunavut | 3 | | Alberta | 3 | | Aercoustics Office - 1004 Middlegate Road, Mississauga | 3 | | 90 Bales Drive East, East Gwillimbury | 3 | | 71 Rexdale Boulevard | 3 | | 500 Commissioners Street | 3 | | 33 Kern road | 3 | | 2400 Royal Windsor Drive, Mississauga, Ontario | 3 | | 150 Toro Road | 3 | | Yellowknife, NT | 2 | | Woodbridge, Ontario | 2 | | Waterloo, ON | 2 | | Vaughan, Ontario | 2 | | Various in Canada | 2 | | Vancouver, British Columbia | 2 | | Toronto, Hybrid | 2 | | Toronto or Ottawa | 2 | | Toronto Office: 317 Adelaide Street West, Toronto | 2 | | Toronto (HQ) - Hybrid | 2 | | Toronto (Gardiner Expressway at Exhibition Station) | 2 | | Toronto & Vancouver | 2 | | Tiverton, Ontario | 2 | | Throughout Toronto | 2 | | TOKYO, JAPAN | 2 | | Stouffville | 2 | | SickKids Research Institute - 686 Bay St. Toronto, ON M5G 0A4 | 2 | | See Notes | 2 | | Santa Clara, California, USA | 2 | | Santa Clara, CA (USA) | 2 | | ST. George Campus | 2 | | Richmond Hill | 2 | | Remote in Canada | 2 | | Remote (HQ located in Montreal) | 2 | | Rankin Inlet or Baker Lake, Nunavut | 2 | | Ottawa/Gatineau | 2 | | Orillia | 2 | | Ontario, Canada | 2 | | One of 71 Rexdale Boulevard OR 715 Milner Avenue | 2 | | One of 500 Commissioners St, 71 Rexdale Blvd, 715 Milner Ave | 2 | | On-site | 2 | | Oakville, Ontario | 2 | | North York, Ontario | 2 | | North York, ON or Chatham, ON | 2 | | Newmarket, ON, CA | 2 | | Multiple locations | 2 | | Mont-Saint-Hilaire, QC | 2 | | Metro Hall, 55 John Street, Toronto, ON | 2 | | Markham, ON, CA | 2 | | Kitchener | 2 | | Hybrid Work Environment - Virtual and/or East Gwillimbury, Ontario | 2 | | Greater Toronto Area | 2 | | Georgetown, ON, Canada | 2 | | Georgetown, ON | 2 | | GTA, London/Guelph, Ottawa | 2 | | GTA | 2 | | Fort Saskatchewan, AB | 2 | | Fort McMurray, Alberta | 2 | | Etobicoke, ON | 2 | | Downtown Toronto or Downtown Ottawa | 2 | | DRDC Ottawa, Shirley's Bay Campus, 3701 Carling Avenue, Ottawa, ON K1A 0Z4 | 2 | | Collingwood ON | 2 | | Cambridge, ON | 2 | | Cambridge | 2 | | Calgary and Various Locations | 2 | | Burnaby, BC | 2 | | Boston, MA, USA | 2 | | Boston, MA | 2 | | Bolton, Ontario | 2 | | Bolton | 2 | | Boisbriand/Mississauga | 2 | | Barrie, ON, CA | 2 | | Barrie | 2 | | Alliston | 2 | | Ajax, Ontario | 2 | | Ajax | 2 | | 95 Arrow Road, M9M 2L4 | 2 | | 901 Simcoe Street South Oshawa | 2 | | 843 Eastern Ave & Union Station | 2 | | 8027 Dixie Rd. Brampton | 2 | | 7455 Birchmount Road, Markham, ON | 2 | | 715 Milner Avenue | 2 | | 71 Rexdale Blvd | 2 | | 6688 Kitimat Rd., Mississauga, ON, L5N 1P8 | 2 | | 60 Wingold Ave, Toronto, Ontario M6B 1P5 | 2 | | 501 Alliance Ave, Suite 406, Toronto, ON | 2 | | 400 Highway 6 North, DUNDAS, ON L9H 7K4 | 2 | | 40 Bertrand Ave, Scarborough, ON M1L 2P6, Canada. | 2 | | 393 University Avenue | 2 | | 3745 Barnes Lake Road - Ashcroft, BC | 2 | | 3484 Semenyk Ct, Mississauga | 2 | | 300 - 3200 Dufferin St | 2 | | 3 Paisley Ln, Uxbridge, ON L9P 0G5 | 2 | | 277 Gladstone Ave. Toronto, Ontario, M6J 3L9 | 2 | | 250 University Avenue Suite 400, Toronto | 2 | | 250 Ferrand Drive | 2 | | 2440 Winston Park Dr, Oakville, ON L6H 7V2 | 2 | | 2425 Matheson Blvd E #200, Mississauga, ON L4W 5K4, Canada | 2 | | 24 Buckingham St, Etobicoke M8Y 2W2 | 2 | | 20 carlson court | 2 | | 1755 Steeles Avenue West, Toronto, ON | 2 | | 1138 Bathurst Street (Bathurst & Dupont) | 2 | | 111 Progress Ave and 333 progress Ave, Scarborough | 2 | | 1 York Street Suite 1010 | 2 | | toronto, ontario | 1 | | Woodbridge, ON | 1 | | West Hill, ON, CA, M1E 2K3 | 1 | | Waterloo/Remote | 1 | | Waterloo, Ontario | 1 | | Wakefield Canada | 1 | | Virtual | 1 | | Victoria, BC | 1 | | Various location in Canada | 1 | | Various in Ontario | 1 | | Various Construction Field Offices within the Metropolitan Toronto area | 1 | | Town of Oakville Town Hall: 1225 Trafalgar Road, Oakville; and Work From Home | 1 | | Toronto/Thornhill | 1 | | Toronto/Barrie, ON | 1 | | Toronto, Ontario OR Montreal, Quebec | 1 | | Toronto, Ontario (Hybrid) | 1 | | Toronto, ON or Calgary, AB | 1 | | Toronto, ON (various locations) | 1 | | Toronto, CA | 1 | | Toronto and Kitchener | 1 | | Toronto OR Gatineau | 1 | | Toronto ON | 1 | | Toronto (Hybrid) | 1 | | Toronto (HQ) - Hybrid - In office once a week | 1 | | Tiverton | 1 | | Thunder Bay, ON | 1 | | Thornhill, ON | 1 | | TORONTO | 1 | | TD Centre, 66 Wellington St W, Toronto | 1 | | Surrey, BC | 1 | | Suite 440, 20 Toronto Street, Toronto, ON M5C 2B8 | 1 | | Sudbury, Ontario | 1 | | Sudbury, ON, CAN | 1 | | Sudbury, ON Canada | 1 | | Strathroy, ON | 1 | | St. Clair River / Toronto | 1 | | St. Catharines, ON | 1 | | Scarborough, Ontario | 1 | | Richmond hill | 1 | | Rexdale, ON, CA | 1 | | Regina | 1 | | Rainbow Lake, AB | 1 | | Princess Margaret Cancer Centre | 1 | | Pickering, ON | 1 | | Peterborough, Ontario | 1 | | Ottawa, Toronto, North Bay | 1 | | Ottawa, On | 1 | | Ottawa (preferred) or remote | 1 | | Orillia, ON, CA | 1 | | Oakville, ON or Toronto, ON | 1 | | OPS office locations in Ontario (Toronto, Oshawa, Guelph, St. Catherines, North Bay, Kingston, Sudbury, London, Ottawa, Newmarket, Hamilton, Thunder Bay, Sault Ste Marie, and Peterborough) and/or remotely following a hybrid model | 1 | | North York, Toronto OR Calgary, Alberta | 1 | | North York, ON or Toronto, ON | 1 | | North Bay | 1 | | Nepean | 1 | | Nanticoke, ON, CA | 1 | | NEWMARKET, ON | 1 | | Munich, Germany (Preferred) or Toronto, Canada | 1 | | Multiple | 1 | | Mountain View, CA | 1 | | Mooretown, ON | 1 | | Montreal, Toronto | 1 | | Montreal, Quebec | 1 | | Mississuaga, ON | 1 | | Mississauga,ON | 1 | | Mississauga, Ontarip | 1 | | Mississauga, On | 1 | | Mississauga, Canada | 1 | | Markhan | 1 | | Markham, ON Canada | 1 | | Markham, Mississauga, OR Ottawa, ON | 1 | | Markham or Oakville | 1 | | Markham or Mississauga, ON | 1 | | Manhattan, NY | 1 | | MaRS Centre, 101 College Street, Toronto | 1 | | London, UK | 1 | | London | 1 | | Lloydminster, AB; Lloydminster, SK | 1 | | Laval, Quebec | 1 | | Lakefield, ON | 1 | | Lake Charles, Louisiana | 1 | | Kingston, ON | 1 | | Kingston (294 King Street East) and/or Toronto (4900 Yonge Street) | 1 | | Kincardine, ON, CA | 1 | | Kincardine | 1 | | Impala Canada | 1 | | Hyrbid, Toronto | 1 | | Hybrid, Toronto | 1 | | Hamilton, Ontario | 1 | | Hamilton and/or Vaughan offices | 1 | | Guelph Office | 1 | | Greater Sudbury, ON | 1 | | GTA, or outskirts of Ontario | 1 | | GTA, London/Guelph, | 1 | | For McMurray | 1 | | Flexible | 1 | | Etobicoke, Ontario/ Remote | 1 | | Edmonton, AB, CA | 1 | | Edmonton or Calgary, AB | 1 | | Dresden, ON | 1 | | Downtown Toronto, Richmond Hill, Vancouver / Virtual | 1 | | Downtown Toronto (remote) | 1 | | Downsview, 123 Garratt Blvd, North York, ON | 1 | | Dorval, Quebec | 1 | | Delta, Canada | 1 | | Copper Cliff, ON | 1 | | Connaught Campus,1755 Steeles Avenue West, Toronto, ON, Canada, M2R 3T4 | 1 | | Concord | 1 |
How many job postings are there for mechatronics positions?
SELECT COUNT(*) AS num_mech_postingsFROM JobPostingWHERE title LIKE '%mechatronic%' OR company LIKE '%mechatronic%' OR companyDivision LIKE '%mechatronic%' OR function LIKE '%mechatronic%' OR description LIKE '%mechatronic%' OR requirements LIKE '%mechatronic%' OR preferredDisciplines LIKE '%mechatronic%';num_mech_postings: 87
What does a job for a mechatronics position look like?
SELECT *FROM JobPostingWHERE title LIKE '%mechatronic%' OR company LIKE '%mechatronic%' OR companyDivision LIKE '%mechatronic%' OR function LIKE '%mechatronic%' OR description LIKE '%mechatronic%' OR requirements LIKE '%mechatronic%' OR preferredDisciplines LIKE '%mechatronic%'LIMIT 1;| id | postingDate | title | company | companyDivision | companyWebsite | location | locationType | numPositions | salary | startDate | endDate | function | |-------|-------------|---------------------------|---------------------|-----------------|----------------------------------------------------------|-------------------|--------------|--------------|---------------------------------------|------------|------------|-------------| | 43873 | 2023-09-18 | Operational Technology Intern | Honda of Canada Mfg | Recruitment | https://www.hondacanadamfg.ca/ | Alliston, Ontario | On-Site | 45 | $26.17 hourly for 40.0 hours per week | 05/06/2024 | 08/25/2025 | Engineering |
Next Steps
Edit (2024-11-11): part 2 of this post series was intended to be about cleaning the data. Unfortunately, I've been so preoccupied with other things (including a better dashboard for 2024-2025 co-op job postings) that I haven't had the time to do any of that 😅, so part 2 ended up being about the dashboard I built to display all this job info on my website. As it is, I'll leave the data cleaning for another day, but I hope you found the initial insights interesting!
~~You'll notice that the data still needs some cleaning[^example], which is fine, should be fairly simple to do by manually parsing through the dataset and aggregating similar values.~~
[^example]: e.g. Toronto and Toronto, ON are present as two distinct locations, when really they should just be one.
~~But after some basic data cleaning is~~ the fun part: analyzing the data to generate some insights on posted jobs, including...
- How many jobs are posted for chemical/mechanical/mineral/... engineers?
- During what periods are the bulk of jobs posted?
- When do specific companies post most/all their jobs?
- How many jobs are reposted[^yeahidkaboutthiseither], and which ones?
- ...and more!
[^yeahidkaboutthiseither]: Something the Engineering Career Centre (ECC) people who run the PEY Co-op job board don't inform you about ahead of time, employers can "repost" a job with the same job id (usually several weeks) after the original which makes it'll show up under New Posting Since Last Login even if you've already viewed (and even though it's technically still the same single job posting). It's not commonplace but it did occur for a few dozen jobs (I imagine for those where the position was left unfilled after some initial batch of students applied and it was reposted to reinvigorate interest).